根据Kafka官网的介绍,Kafka是一个分布式流平台,这个介绍的真正含义是什么呢?
流平台主要由三个关键的能力:
发布和订阅记录流,类似于消息队列
以容错的方式持久化存储流数据
处理流式数据
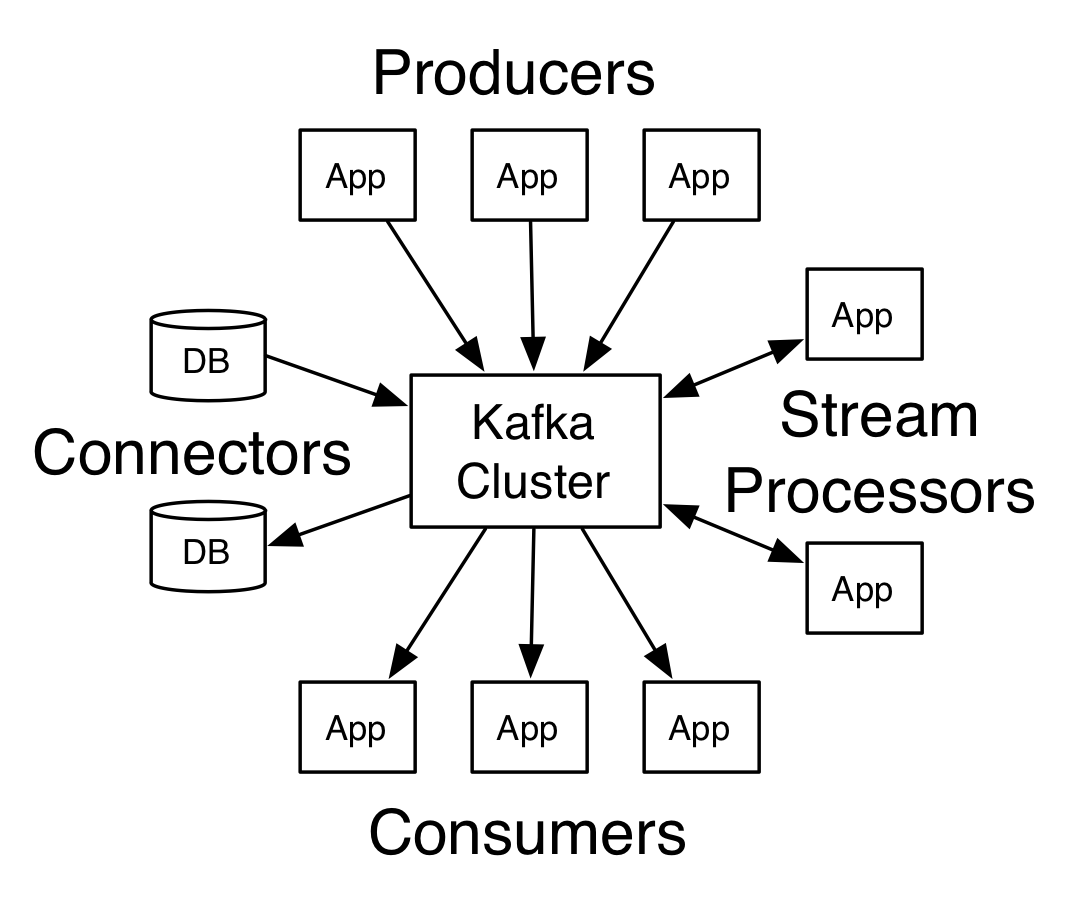
Kafka通常被用于两大类应用:
- 建立实时数据管道,在各个系统或应用间可靠地获取数据
- 建立实时流失应用去传输或者是处理流式数据
为了了解kafka是如何实现这些功能的,我们要从头到尾了解kafka的构成。
首先要了解一些概念:
- kafka是集群部署的,可以跨越多个数据中心
- kafka集群按类存储流式数据,这些类别被称为topics
- 每一条数据由key,value和timestamp组成
kafka主要有四类核心api:
- Producer API:允许应用发布流式数据到一个或多个kafka的topic上
- Consumer API:允许应用订阅一个或多个topic,并处理其生成的数据流
- Streams API:允许应用扮演流处理器的功能,从一个或多个topic中消费输入流,并产生一个输出流到一个或多个topic中,高效的将输入流转换为输出流
- Connector API:允许建立和运行一个可复用的producer或consumer,将kafka的topics连接到已经存在的应用或数据系统中。比如,connector可以连接到一个关系型数据库,以监测数据库表的所有变化。
kafka专用术语:
Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
Producer:负责发布消息到 Kafka broker。
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
Partition offset:每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
Replicas of partition:副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower的partition中消费数据,而是从为leader的partition中读取数据。
Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
zookeeper的作用:
- Zookeeper:Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
topics和logs
topic是消息发布的类别,在kafka中,topic总是有多个订阅者的,也就是说,可以有0个,1个或多个消费者去订阅写入的数据。
对于每一个topic,kafka集群保存一个分类log,如下:

每一个分类是一个有序的,不可数的记录序列,数据每次选择一个partion添加到最后。选择的partion号和在partion中的offset唯一定义了一条记录。
kafka集群会持久化消息数据,不管这条消息是否被消费。这个记录的周期是可以配置的,比如你设置为2天,那么一条消息被发布后,会持久化两天,然后被删除。
实际上,为每一个消费者存储的元数据只有消费的offeset,消费者可以控制offset的位置,比如跳过一些中间内容,直接消费最新的内容也是可以做到的。

发布
每一个partition有一个服务器扮演leader角色,有0个或多个服务器扮演follower角色。leader处理所有当前partion的读写请求,follower只是被动地复制leader,如果leader机宕机,剩下的follower中会自动产生新的leader。
一个消费者订阅数据:
- 生产者将数据发送到指定topic中
- Kafka将数据以partition的方式存储到broker上。Kafka支持数据均衡,例如生产者生成了两条消息,topic有两个partition,那么Kafka将在两个partition上分别存储一条消息
- 消费者订阅指定topic的数据
- 当消费者订阅topic中消息时,Kafka将当前的offset发给消费者,同时将offset存储到Zookeeper中
- 消费者以特定的间隔(如100ms)向Kafka请求数据
- 当Kafka接收到生产者发送的数据时,Kafka将这些数据推送给消费者
- 消费者受到Kafka推送的数据,并进行处理
- 当消费者处理完该条消息后,消费者向Kafka broker发送一个该消息已被消费的反馈
- 当Kafka接到消费者的反馈后,Kafka更新offset包括Zookeeper中的offset。
- 以上过程一直重复,直到消费者停止请求数据
- 消费者可以重置offset,从而可以灵活消费存储在Kafka上的数据
消费者组数据消费流程
Kafka支持消费者组内的多个消费者同时消费一个topic,一个消费者组由具有同一个Group ID的多个消费者组成。具体流程如下:
- 生产者发送数据到指定的topic
- Kafka将数据存储到broker上的partition中
- 假设现在有一个消费者订阅了一个topic,topic名字为“test”,消费者的Group ID为“Group1”
- 此时Kafka的处理方式与只有一个消费者的情况一样
- 当Kafka接收到一个同样Group ID为“Group1”、消费的topic同样为“test”的消费者的请求时,Kafka把数据操作模式切换为分享模式,此时数据将在两个消费者上共享。
- 当消费者的数目超过topic的partition数目时,后来的消费者将消费不到Kafka中的数据。因为在Kafka给每一个消费者消费者至少分配一个partition,一旦partition都被指派给消费者了,新来的消费者将不会再分配partition。即一个partition只能分配给一个消费者,一个消费者可以消费多个partition。