安装: 下载并开始使用Flink
Flink 可以运行在 Linux, Mac OS X和Windows上。为了运行Flink, 唯一的要求是必须在Java 7.x (或者更高版本)上安装。Windows 用户, 请查看 Flink在Windows上的安装指南。
你可以使用以下命令检查Java当前运行的版本:
1 | java -version |
如果你有安装Java 8,命令行有如下回显
1 | java version "1.8.0_111" |
**下载和解压 **
- 从下载页下载一个二进制的包,你可以选择任何你喜欢的Hadoop/Scala组合包。如果你计划使用文件系统,那么可以使用任何Hadoop版本。
- 进入下载目录
- 解压下载的压缩包
1 | $ cd ~/Downloads # Go to download directory |
MacOS X
对于 MacOS X 用户, Flink 可以通过Homebrew 进行安装。
1 | ~~~bash |
使用maven可以直接常见一个flink项目
1 | $ mvn archetype:generate \ |
其中的groupId和ArtifactId可以按照自己的需要修改
建好的工程项目结构如下
1 | $ tree wiki-edits |
此时的pom.xml已经包含了flink的依赖,在java文件夹下有几个示例文件,可以将其删除,然后从0开始
1 | $ rm wiki-edits/src/main/java/wikiedits/*.java |
最后我们需要在pom.xml中添加对维基百科的连接器,修改后的dependencies如下:
1 | <dependencies> |
使用idea创建一个flink项目
先用idea的maven创建一个scala项目
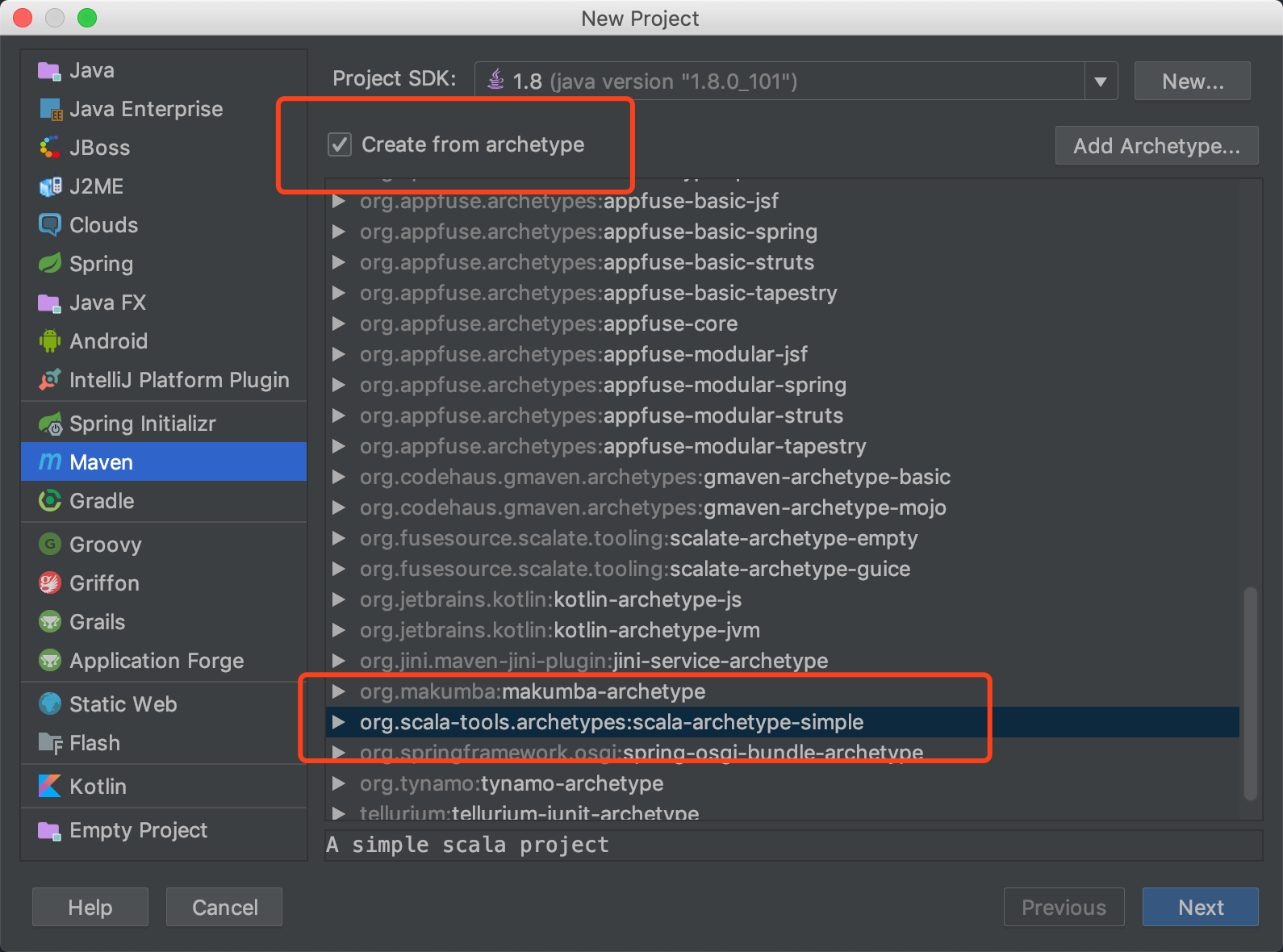
在pom.xml中加入以下flink相关的依赖,记得保持Scala的版本和flink的版本相同,不然会报错
1 | <!-- Use this dependency if you are using the DataStream API --> |
如果出现无法更新的状况,打开设置,勾选always update snapshots

出现更新慢的情况,可以将maven的配置加入阿里云镜像
1 | <mirrors> |
同时将sbt加入镜像,新建~/.sbt/repositories,修改其内容为:
1 | [repositories] |
再次更新maven依赖即可
编写一个flink程序
导入刚才maven建立的项目,新建一个src/main/java/wikiedits/WikipediaAnalysis.java类:
1 | package wikiedits; |
现在程序还很基础,我们将一步一步填充程序内容。最后也将列出完整程序。
编写flink程序的第一步是要创建一个StreamExecutionEnvironment对象 (如果是批处理的话,建立ExecutionEnvironment对象),这个对象将被用于设置执行参数,以及创建外部的数据输入源。
1 | StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment(); |
接下来我们创建一个源,从维基百科的IRC log读取数据
1 | DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource()); |
至此我们创建了一个包含WikipediaEditEvent的DataStream对象,可以用于之后的处理。本例中,我们最重要挖掘的内容是,每个用户在特定窗口时间内添加或删除的字节数,比如五秒钟。因此,我们首先要将流在用户名上进行统计,也就是说对这个流的处理要讲用户名考虑在内。在这个例子中,特定时间内修改的字节数的和应该是对应到每个独立用户的。为了对某个数据流进行标记,我们要创建一个KeySelector,如下:
1 | KeyedStream<WikipediaEditEvent, String> keyedEdits = edits |
上面的操作给我们提供了一个包含string key的WikipediaEditEvent,其key为用户名。
现在我们可以指定我们想要的windows size,并在这个数据流中计算我们想要的结果。在对无线数据流计算聚合结果的时候,窗口大小是一个必须的参数。在本例中,我们计算窗口大小为5s的聚合结果。
1 | DataStream<Tuple2<String, Long>> result = keyedEdits |
第一个函数TimeWindow定义了一个大小为5s的,不重叠的时间窗口。第二个函数为每个特定的key,在每个窗口上指定了一个fold transformation。在该例中,初始值为(“”,0L),并对其加上每个用户在时间窗口内,每次修改的byte difference。结果流Tuple2<String, Long>,包含了每个用户在每个时间窗口内的修改byte数量。
最后一件事情就是打印结果和开始执行
1 | result.print(); |
完整程序如下:
1 | package wikiedits; |
Flink API概念
Flink程序是实现分布式数据变换的常用程序(例如,filtering, mapping, updating state, joining, grouping, defining windows, aggregating)。 数据从source创建(例如,通过从文件,kafka topics或从本地的内存数据中读取)。结果通过sinks(接收器)返回,结果可以写入(分布式)文件或标准输出(例如,命令行终端)。 Flink程序可以在各种环境中运行,独立运行或嵌入其他程序中。 既可以在本地JVM中执行,也可以在多计算机的集群上执行。
根据数据源的类型,如有界(bounded)或无界(unbounded)源,您可以编写批处理(batch)程序或流处理(stream)程序,其中DataSet API用于批处理,DataStream API用于流式处理。 本指南将介绍两种API共有的基本概念。流式数据处理教程请参见流式数据处理,批处理教程请参加批处理。
DataSet和DataStream
Flink具有特殊类DataSet和DataStream来表示程序中的数据。 您可以将它们视为可以包含重复项的不可变数据集合。 在DataSet的情况下,数据是有限的,而对于DataStream,元素的数量可以是无限的。
这些集合在某些关键方面与常规Java集合不同。 首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。 你也不能简单地检查里面的元素。
通过在Flink程序中添加源来创建集合,并通过使用诸如map,filter等API方法对它们进行转换来从这些集合中派生新集合。
Flink程序的剖析
Flink程序看起来像是转换数据集合的常规程序。 每个程序包含相同的基本部分:
- 获得执行环境,Obtain an execution environment,
- 加载/创建初始数据,Load/create the initial data,
- 指定此数据的转换,Specify transformations on this data,
- 指定放置计算结果的位置,Specify where to put the results of your computations,
- 触发程序执行,Trigger the program execution
我们现在将概述每个步骤,请参阅相应部分以获取更多详细信息。 请注意,Java DataSet API的所有核心类都可以在org.apache.flink.api.java包中找到,而Java DataStream API的类可以在org.apache.flink.streaming.api中找到。
StreamExecutionEnvironment是所有Flink程序的基础。 您可以在StreamExecutionEnvironment上使用这些静态方法获取一个StreamExecutionEnvironment实例:
1 | getExecutionEnvironment() |
通常,您只需要使用getExecutionEnvironment(),因为这将根据上下文执行正确的操作:如果您在IDE中执行程序或作为常规Java程序执行,它将创建一个本地环境,在你的本地机器执行程序。 如果您从程序中创建了一个JAR文件,并通过命令行调用它,则Flink集群管理器将执行您的main方法,同时getExecutionEnvironment()方法将返回一个执行环境,用于在集群上执行你的程序。
为了指定数据源,执行环境有几种方法可以从文件中读取数据:你可以逐行读,作为csv文监督,或者完全用一个你自定义的格式读取。为了读取一个text文件为一个序列,你可以用:
1 | final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
这将为为你供一个DataStream,然后你可以对其应用transformation来创建新的派生DataStream。
您可以通过使用transformation函数,调用DataStream上的方法来应用转换。 例如,map函数转换如下所示:
1 | DataStream<String> input = ...; |
这将原始集合中的每个String转换为Integer来创建新的DataStream。
一旦有了包含最终结果的DataStream,就可以通过创建接收器将其写入外部系统。下面是一个接收器sinks的示例:
1 | writeAsText(String path) |
一旦指定了完整的程序,就需要通过调用StreamExecutionEnvironment上的execute()来触发程序执行。 根据ExecutionEnvironment的类型,决定在本地计算机上执行或提交程序在集群上执行。
execute()方法返回一个JobExecutionResult,它包含执行次数和累计结果。
懒惰执行
所有Flink程序都是懒惰地执行:当执行程序的main方法时,数据加载和转换不会直接发生。 而是创建每个操作并将其添加到程序的计划中。 实际执行操作是在调用环境上的execute()方法后发生的,。 程序是在本地执行还是在集群上执行取决于执行环境的类型
懒惰的评估可以使构建Flink作为一个整体,添加各个单元以执行复杂的程序。
指定keys
某些数据变换(join,coGroup,keyBy,groupBy)要求在元素集合上定义keys。 其他转换(Reduce,GroupReduce,Aggregate,Windows)允许数据根据之前应用的key来分组。
A DataSet is grouped as:
1 | DataSet<...> input = // [...] |
Flink的数据模型不基于键值对。 因此,您无需将数据集类型物理打包到键和值中。 键是“虚拟的”:它们被定义为实际数据上的函数,以指导分组操作符。
注意:在下面的讨论中,我们将使用DataStream API和keyBy。 对于DataSet API,您只需要用DataSet和groupBy替换。
为Tuple定义keys
最简单的情况是在元组的一个或多个字段上对元组进行分组:
1 | DataStream<Tuple3<Integer,String,Long>> input = // [...] |
元组在第一个字段(整数类型)上分组。
在这里,我们将元组分组在由第一个和第二个字段组成的复合键上。
关于嵌套元组的注释:如果你有一个带有嵌套元组的DataStream,例如:
1 | DataStream<Tuple3<Tuple2<Integer, Float>,String,Long>> ds; |
指定keyBy(0)将使系统使用完整的Tuple2作为键(以Integer和Float为键)。 如果要“导航”到嵌套的Tuple2中,则必须使用下面解释的字段表达式键。
用字段表达式定义keys
您可以使用基于字符串的字段表达式来引用嵌套字段,并定义用于分组,排序,连接或coGrouping的键。
字段表达式可以非常轻松地选择(嵌套)复合类型中的字段,例如Tuple和POJO类型。
在下面的示例中,我们有一个WC POJO,其中包含两个字段“word”和“count”。 要按字段分组,我们只需将其名称传递给keyBy()函数。
1 | // some ordinary POJO (Plain old Java Object) |
字段表达式语法:
- 按字段名称选择POJO字段。 例如,“user”指的是POJO类型的“user”字段。
- 按字段名称或0偏移字段索引选择元组字段。 例如,“f0”和“5”分别表示Java元组类型的第一和第六字段。
- 您可以在POJO和Tuples中选择嵌套字段。 例如,“user.zip”指的是POJO的“zip”字段,其存储在POJO类型的“user”字段中。 支持任意嵌套和混合POJO和元组,例如“f1.user.zip”或“user.f3.1.zip”。
- 您可以使用“*”通配符表达式选择完整类型。 这也适用于非Tuple或POJO类型的类型。
1 | public static class WC { |
下面展示了几个上面示例代码的有效字段表达式:
“count”:WC类中的count字段。
“complex”:递归选择POJO类型ComplexNestedClass的字段复合体的所有字段。
“complex.word.f2”:选择嵌套Tuple3的最后一个字段。
“complex.hadoopCitizen”:选择Hadoop IntWritable类型。
用key selector函数定义keys
定义keys的另一种方法是“key selector”函数。 key selector函数将单个元素作为输入,并返回元素的键。 keys可以是任何类型,并且可以从确定性计算中导出。
以下示例显示了一个key selector函数,它只返回一个对象的字段:
1 | // some ordinary POJO |
指定transformation函数
大多数转换都需要用户定义的函数。 本节列出了如何指定它们的不同方法
实现一个接口
最基本的方法是实现一个提供的接口:
1 | class MyMapFunction implements MapFunction<String, Integer> { |
匿名类
您可以将函数作为匿名类传递:
1 | data.map(new MapFunction<String, Integer> () { |
Java 8 Lambdas表达式
Flink还支持Java API中的Java 8 Lambdas:
1 | data.filter(s -> s.startsWith("http://")); |
富函数(rich functions)
需要用户定义函数的所有变换,都可以将富函数作为参数。 例如:
1 | class MyMapFunction implements MapFunction<String, Integer> { |
可以改写为:
1 | class MyMapFunction extends RichMapFunction<String, Integer> { |
再把这个函数传给一个普通的map变换:
1 | data.map(new MyMapFunction()); |
富函数也可以被定义为匿名类
1 | data.map (new RichMapFunction<String, Integer>() { |
除了用户定义的函数(map,reduce等)之外,Rich函数还提供了四种方法:open,close,getRuntimeContext和setRuntimeContext。 这些对于将函数参数化有很大的用处(具体参考为函数传参),创建和完成本地状态,访问广播变量,以及访问运行时信息(比如累计器和计数器),以及迭代器的信息。
支持的数据类型
Flink对DataSet或DataStream中可以包含的元素类型设置了一些限制。 原因是系统需要对类型分析,以确定有效的执行策略。
flink支持六种不同类别的数据类型:
- Java元组和Scala案例类,Java Tuples and Scala Case Classes
- Java POJOs
- 原始类型,Primitive Types
- 常规类,Regular Classes
- 值,Values
- Hadoop Writables
- 特殊类型,Special Types
Tuples and Case Classes
元组是包含固定数量的具有各种类型的字段的复合类型。 Java API提供从Tuple1到Tuple25的类。 元组的每个字段都可以是包含更多元组的任意Flink类型,从而产生嵌套元组。 可以使用字段名称tuple.f4直接访问元组的字段,也可以使用通用getter方法tuple.getField(int position)。 字段索引从0开始。请注意,这与Scala元组形成对比,但它与Java的一般索引更为一致。
1 | DataStream<Tuple2<String, Integer>> wordCounts = env.fromElements( |
POJOs
如果满足以下要求,则Flink将Java和Scala类视为特殊的POJO数据类型:
- 这个类必须是public的
- 它必须有一个没有参数的public构造函数(默认构造函数)。
- 所有字段都是public的,或者可以通过getter和setter函数访问。 对于名为foo的字段,getter和setter方法必须命名为
getFoo()和setFoo()。 - Flink必须支持字段的类型。 目前,Flink使用Avro序列化任意对象(例如Date)。
- Flink分析POJO类型的结构,即它了解POJO的字段。 因此,POJO类型比一般类型更容易使用。 此外,Flink可以比一般类型更有效地处理POJO。
以下示例显示了一个包含两个public字段的简单POJO。
1 | public class WordWithCount { |
原始类型
Flink支持所有Java和Scala原语类型,如Integer,String和Double。
常规类
Flink支持大多数Java和Scala类(API和自定义)。 限制适用于包含无法序列化的字段的类,如文件指针,I/O流或其他本机资源。 遵循Java Beans约定的类通常可以很好地工作。
所有未标识为POJO类型的类(请参阅上面的POJO要求)都由Flink作为常规类类型处理。 Flink将这些数据类型视为黑盒子,并且无法访问其内容(即,用于有效排序)。 使用序列化框架Kryo对常规类型进行反序列化。
值
值类型手动描述其序列化和反序列化。它们不通过通用序列化框架进行序列化,而是通过使用读取和写入方法实现org.apache.flinktypes.Value接口来为这些操作提供自定义代码。当通用序列化方法效率非常低时,使用值类型是合理的。一个示例是将元素的稀疏向量实现为数组的数据类型。知道数组大部分为零,可以对非零元素使用特殊编码,而通用序列化只需编写所有数组元素。
org.apache.flinktypes.CopyableValue接口以类似的方式支持手动内部克隆逻辑。
Flink带有与基本数据类型对应的预定义值类型。 (ByteValue,ShortValue,IntValue,LongValue,FloatValue,DoubleValue,StringValue,CharValue,BooleanValue)。这些Value类型充当基本数据类型的可变变体:它们的值可以更改,允许程序员重用对象并减轻垃圾收集器的压力。
类型擦除和类型推断
注意:本节仅适用于Java。
Java编译器在编译后抛弃了大部分泛型类型信息。这在Java中称为类型擦除。这意味着在运行时,对象的实例不再知道其泛型类型。例如,DataStream<String>和DataStream<Long>的实例与JVM看起来相同。
Flink在准备执行程序时(当调用程序的主要方法时)需要类型信息。 Flink Java API尝试重建以各种方式丢弃的类型信息,并将其显式存储在数据集和运算符中。可以通过DataStream.getType()检索类型。该方法返回TypeInformation的一个实例,这是Flink表示类型的内部方式。
类型推断有其局限性,在某些情况下需要程序员的“合作”。这方面的示例是从集合创建数据集的方法,例如ExecutionEnvironment.fromCollection(),你可以在其中传递描述类型的参数。但是像MapFunction <I,O>这样的通用函数也可能需要额外的类型信息。
ResultTypeQueryable接口可以通过输入格式和函数实现,以明确告知API其返回类型。调用函数的输入类型通常可以通过先前操作的结果类型来推断。
累计器和计数器
累加器是具有添加操作和最终累积结果的简单构造,可在任务结束后使用。
最直接的累加器是一个计数器:您可以使用Accumulator.add(V值)方法递增它。 在任务结束时,Flink将汇总(合并)所有部分结果并将结果发送给客户。 在调试过程中,或者如果您想快速了解有关数据的更多信息,累加器非常有用。
Flink目前有以下内置累加器。 它们中的每一个都实现了Accumulator接口。
- IntCounter,LongCounter和DoubleCounter:请参阅下面的使用计数器的示例。
- 直方图:离散数量的区间的直方图实现。 在内部,它只是一个从Integer到Integer的映射。 您可以使用它来计算值的分布,例如 字数统计程序的每行字数分布。
如何使用累计器
首先,您必须在需要使用它的用户定义的转换函数中创建累加器对象(此处为计数器)。
1 | private IntCounter numLines = new IntCounter(); |
其次,您必须注册累加器对象,通常在富函数的open()方法中。 在这里您还可以定义名称。
1 | getRuntimeContext().addAccumulator("num-lines", this.numLines); |
您现在可以在运算符函数中的任何位置使用累加器,包括open()和close()方法。
1 | this.numLines.add(1); |
整个结果将存储在JobExecutionResult对象中,该对象是从执行环境的execute()方法返回的(目前这仅在执行等待任务完成时才有效)。
1 | myJobExecutionResult.getAccumulatorResult("num-lines") |
所有累加器每个作业共享一个命名空间。 因此,您可以在任务的不同操作函数中使用相同的累加器。 Flink将在内部合并所有具有相同名称的累加器。
关于累加器和迭代的注释:目前累加器的结果仅在整个任务结束后才可用。 flink还计划在下一次迭代中使前一次迭代的结果可用。 您可以使用聚合器来计算每次迭代统计信息,并根据此类统计信息确定迭代的终止。
####自定义累加器
要实现自己的累加器,只需编写Accumulator接口的实现即可。 如果您认为您的自定义累加器应与Flink一共同使用,请随意创建pull请求。
您可以选择实现Accumulator或SimpleAccumulator。
累加器<V,R>最灵活:它为要添加的值定义类型V,为最终结果定义结果类型R. 例如。 对于直方图,V是数字,R是直方图。 SimpleAccumulator适用于两种类型相同的情况,例如计数器。