基础语法
大多数语法与c++相似,只记录部分不熟悉的或者是不一样的语法。
static关键字
static的作用是,用static修饰的部分,不需要实例化类,可以直接通过类名+”.”来使用
static还可以用来修饰变量,如果被static修饰之后,在内存中只有一个拷贝,只分配一次内存,没有用static修饰的在内存中有多个拷贝,每次new都会分配一个新地址
运算符
^:异或操作符&和&&符号的区别:&符号两边的运算都要执行,&&只有在左边条件为真的时候才执行,例如if(str!=null && !"".equals(str)):- 用
&&的时候,此时如果str!=null,右边的!"".equals(str)会被执行,如果此时str=null,那么右边的!"".equals(str)不会被执行; - 如果用
&:不管str!=null的结果如何,后面的!"".equals(str)都会被执行
- 用
>>>:无符号右移操作
foreach
如果要遍历一个数组,可以使用在java SE5中引入的foreach方法:for(int i : range(10))
1 | Random rand = new Random(); |
构造器和垃圾回收器
构造器
构造器就相当于js当中的构造函数,python中的__init__函数,在java当中构造器的名称就是和类名相同的一个函数
1 | class Rock2{ |
方法重载
方法重载就是同一个函数,在其参数不同的时候执行不同的函数的过程,比如:
1 | class Tree{ |
在构造函数中调用构造函数
一个class可以有多个构造函数,还可以在某个构造函数中调用另一个构造函数,调用的方法是用this(构造参数)来实现的,注意:在一个构造其中最多只能调用一次别的构造函数,因为某个class只能被构造一次。且只能在构造函数中调用构造函数,还要在构造函数的最前面调用。
1 | class Flower { |
垃圾回收
所有用new构建的对象,java都会自动回收,只有那些不是用new得到的对象所占用的内存,java无法处理,需要你编写finalize()函数来进行垃圾回收
- 对象可能不被垃圾回收
- 垃圾回收不等于“析构”
- 垃圾回收只与内存有关
因为垃圾回收本身也要消耗一定资源,所以在jvm内存耗尽之前,它是不会浪费时间去执行垃圾回收的。
在垃圾回收的时候,会自动调用finalize()函数,通常是一些销毁时对对象的验证
1 | public class Main { |
垃圾回收的自适应技术
所谓的自适应,就是在两种垃圾回收方式中切换:标记-清扫模式和停止-复制模式
先来介绍一下这两种模式的工作机理:
- 标记-清扫模式:遍历所有的引用,找出存活的对象。每找到一个存活对象,就会给对象一个标记,这个过程不会回收任何对象。只有标记完所有对象的时候,才开始清理,没有标记的对象将被释放。剩下的空间是不连续的,如果希望得到连续空间,就需要重新整理剩下的对象。
- 停止-复制模式:暂停程序运行,将所有存活的对象从当前堆复制到另一个堆,没有被复制到都是垃圾。得到的新堆是连续的。这种方法需要两倍的程序运行内存(一个本身,一个复制堆),在程序稳定时只有少量垃圾,大量复制会产生内存浪费。
自适应模式:如果对象很稳定,就切换到“标记-清扫”模式;要是标记清扫模式的堆空间中出现很多碎片,就会切换回“停止-复制”模式
类成员初始化顺序
首先被初始化的是静态变量,然后是普通变量,比如定义的int,或者是定义的new 类元素,然后是构造器,最后是函数对象
1 |
|
静态数据
无论创建多少个对象,静态数据都只占用一份存储区域,static不能用于局部变量,且静态变量的初始化优先级最高,在最前面
1 |
|
静态方法:静态方法不能访问this变量,但静态方法可以访问静态变量
数组初始化
数组在java中的定义形式推荐的是:
1 | int[] array; |
方括号在前,定义的是一个int类型的数组,比在后面更容易理解
数组的初始化有三种方法,
- 第一种是先定义长度,然后遍历数组,一个个赋值
- 第二种是用大括号直接赋值
- 第三种是用new+类型名[]+{值}
1 |
|
数组排序
可以自己写冒泡排序:
1 | for (int i = 0; i < ns.length; i++) { |
也可以直接调用Arrays.sort方法
1 | int[] ns=[1,33,4,2,5] |
打印数组的方法:
1 | //方法一 Arrays.toString或者Arrays.deeptoString(打印多维数组) |
tips:
idea快捷键:
psvm:快速创建main函数sout:快速输入System.out.println()fori:快速创建for模板
可变参数列表
在java se5之前用的方法是输入内容放在args里面
1 | public class VarArgs { |
在se5之后,就可以直接使用可变参数了,这与之前看的javascript的多参数用法一样,与python的*args一样,用法是... args
1 | public class NewVarArgs { |
枚举enum
枚举可以用于switch语句,自带ordinal()方法用于得到index,和values方法用于创建数组
1 | public static void main(String[] args) { |
访问权限控制
包
一个包里面有多各类,然而有且仅有一个public类与包的名字相同,其他类主要为public类提供支持
包定义与引用
声明包的方法是用package关键字
1 | package my.mypackage |
引用的方法可以写全包名+类名,或者是使用import 包名
访问权限控制
public:都可以访问
private:只有拥有成员的当前类可以访问
protected:当前和继承的对象可以访问
封装
将类中的属性标记为private,外部代码不可以直接访问类元素,而是通过一些封装好的函数来访问,比如
1 | public class Person { |
重载和重写
重载:与父类的函数名相同,返回值类型相同,但是参数类型不同
重写(覆写):与父类的函数名和参数都相同,只是函数内容不同
se5中引入了一个@override关键字,在你想要重写的时候,可以把这个关键字放在返回值之前,如果不是重写,那么将会报错
1 | class Lisa extends Homer{ |
继承
关键字extends,子类继承了父类所有元素和方法,可以重写这些方法
java只允许单继承,也就是每个类只能有一个父类
用super()表示父类的构造方法,用super.函数名()调用父类中被覆写的方法
1 | public class Student extends Person{ |
向上向下转型
在java中,一个类型可以安全地向上转型,因为一个子类肯定包含父类的所有元素和方法,但是父类不一定能够安全地向下转型。
转型之前先用instanceof判断
1 | if (p instanceof Student){ |
多态
java的方法调用总是作用于对象的实际类型
如果一个变量的声明类型和实际类型值不同,那么他调用方法的时候,调用的是实际类型的方法
在java中,多态的含义是:
- 针对某个类型的方法调用,其真正执行的方法取决于运行时期的实际类型的方法
- 对某个类型调用某个方法,执行的方法可能是某个子类的覆写方法
- 利用多态,允许添加更多类型的子类实现功能扩展
1 | public class Hello { |
java中所有类都继承于object,因此拥有object的所有方法,object中定义了如下的重要方法
toString:把instance输出为Stringequals:判断两个instance是否逻辑相等hashCode:计算一个instance的hash值
final
用
final关键字修饰的方法不能被override用
final关键字修饰的类不能被继承用
final关键字修饰的字段在初始化之后不能被修改
抽象类
如果一个类包含一个抽象方法,那么这个类就是抽象类
抽象方法:就是一个只有函数名,但是没有函数主体
用abstract关键字修饰,抽象方法无法被实例化,但其子类可以被实例化
1 | public abstract class Person{ |
抽象方法的作用就是用来被继承
从抽象类继承的子类必须实现抽象方法,不然该子类仍是一个抽象类
1 | public class Rectangle extends Shape { |
接口
如果一个抽象类没有字段,并且所有方法都是抽象方法,那么我们就可以把这个抽象类改写为接口
接口用interface进行声明,接口默认的是public和abstract,所以在定义接口的时候不用写public和abstract
1 | public interface Shape { |
default关键字可以实现interface的默认方法,这样就不必在每个implements中实现这个方法
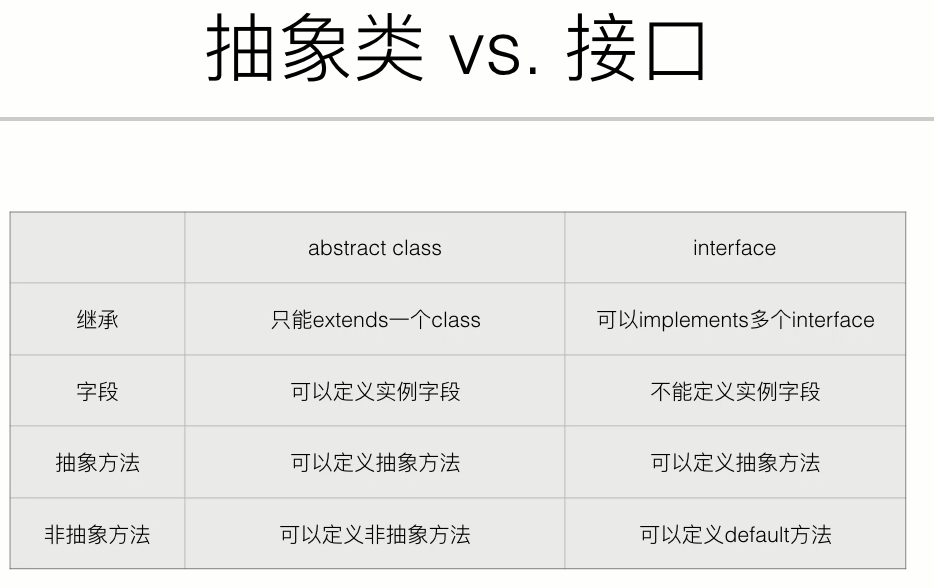
一个接口可以用extends继承另一个接口
包
java定义的名字空间叫做包,用于解决名字冲突的问题
1 | package xiaoming; |
1 | package xiaohong; |
小明的Person类:xiaoming.Person
小红的Person类:xiaohong.Person
包作用域
同一个包中的类,可以访问包作用域的字段和方法
包作用域就是不使用任何public,private,protected修饰的字段和方法
classpath
classpath是一个环境变量,定义java如何搜索class的路径,在windows中用分号;分割,在Linux和mac中用冒号:分割,如果目录含有空格,这个路径就要用双引号括起来
先找当前目录,然后找classpathPATH的路径
运行java的时候可以通过java -cp classpath指定当前运行java时候的classpath
jar包
jar包是一种zip格式的压缩文件,包含若干个.class文件
jar包相当于目录,classpath可以包含jar文件
一个jar包中可以包含另一个jar包
JDK自带的class叫做rt.jar
idea打包jar包的方法
1.选择菜单File->Project Structure,将弹出Project Structure的设置对话框。
2.选择左边的Artifacts后点击上方的“+”按钮
3.在弹出的框中选择jar->from moduls with dependencies..
4.选择要启动的类,然后 确定
5.应用之后选择菜单Build->Build Artifacts,选择Build或者Rebuild后即可生成,生成的jar文件位于工程项目目录的out/artifacts下。
String字符串类型
String可以不用new来实例化,可以通过双引号String s = "xxx"直接赋值
String的内容是不可以变的,对比两个string是否相同要调用string的equal方法,equalIgnoreCase,这个方法可以忽略大小写
String提供的方法:
- contains:查看是否包含子串
- indexOf:找到子串的索引位置
- lastIndexOf:从后向前找
- startswith:返回字符串是否由某个子串开始
- endwith:返回字符串是否由某个子串结束
- trim:移除首位的空白字符,
String S = "\t abc\r\n ;String S2 = S.trim()" - substring:提取子串,
String S="hello, world"; String S1 = S.substring(7)//"world";s.substring(1,5)//"ello",从0开始,包含最后一个数字 - toUppercase, toLowerCase:转换大小写
- replace:替换子串
- replaceAll:用正则表达式替换子串
- join:将一个String数组连接成一个字符串
- valueOf:将一个整型转换为一个string类型,也可以用tostring方法转换为字符串
- Interger.parseInt(“123”):将一个String类型转换为一个int类型
- toCharArray():将String转换为char数组,
String s ="hello; char[] c = s.toCharArray();" - getBytes(“UTF-8”):将string转换为bytes
打印一个array的方法:Arrays.toString(array)
UTF-8和unicode的区别:utf-8是变长的,1-6个字节不等(英文字母只占用1个字节,节省内存)。而unicode所有内容都是2个字节的编码
StringBuilder
StringBuilder是一个支持链式操作的字符串拼接对象,可以不停地apped,然后用toString变成需要的字符串
1 | public static void main(String[] args) { |
JavaBean
很多java类都是先定义一堆private字段,然后定义相应的get和set方法,这样的类就称为JavaBean
在idea中,定义完一个private字段,在字段上点击alt+enter,就可以快速生成get和set方法
enum枚举类
用于定义枚举常量
1 | public enum Person { |
1 | public static void main(String[] args) { |
1 | System.out.println(Person.valueOf("a").name()); |
jdk常用工具类
Math类用于数学计算
Math有random方法,可以生成一个0-1之间的数
0<=x<1Random类用于构建伪随机数
使用之前要先实例化random1
2
3
4
5
6
7
8
9
10
11
12public static void main(String[] args) {
Random r = new Random();
System.out.println(r.nextInt());
System.out.println(r.nextLong());
System.out.println(r.nextFloat());//0-1之间的float
System.out.println(r.nextDouble());//0-1之间的double
}
//结果
//453685453
//-6144617524281204827
//0.8796719
//0.9157346073901224
异常处理
异常
异常处理的方式是用try,catch
java中必须捕获的异常是Exception及其子类,但不包括RuntimeException及其子类
因为error是发生了严重错误,程序本身是无法处理的;而exception是运行时候的逻辑错误,程序可以捕获和处理这些错误,而RuntimeException是因为程序自身有bug,需要我们去修复程序
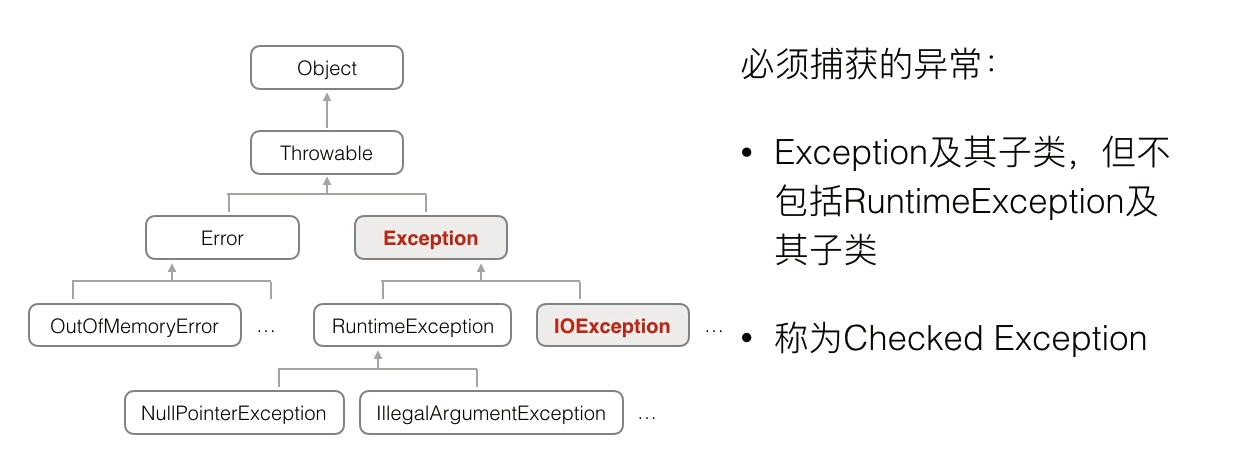
Main方法是捕获异常的最后机会,其余子函数可以用throws将异常抛出,由上层方法来捕获
异常捕获的顺序
异常是按照catch的顺序依次捕获的,所以要把更小的异常(子类)放在前面,不然父类在前面,只要发生了错误就一定会被执行
finally
无论是否有错都要执行就用finally
multi-catch
可以用或操作符|来同时捕获多个Exception
printStackTrace
printStackTrace()方法可以打印出异常的传播路径,对于调试很有用
1 | public class Main { |
JDK已定义的异常

自定义异常
自定义异常,最好使用RuntimeException继承得到,其构造方法可以通过ide提供的alt+insert插入父类的构造方法
1 | package test; |
1 | package test; |
断言
assert关键字,如果条件为true则继续执行,条件为false则抛出AssertionError,可以加入一个断言消息,打印出断言结果
断言是一种条件方式,只能在开发和测试阶段使用
1 | assert x>0: "x<0 now"+x; |
日志
jkd自带的日志系统在java.utils.logging,可以定义格式或者是重定向到文件等
1 | public class Main { |
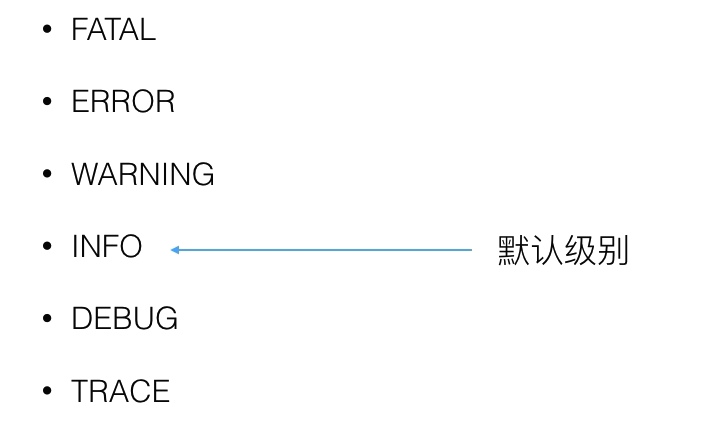
common logging
更常用的log方法是commom logging,一共六个日志级别如下
tips:
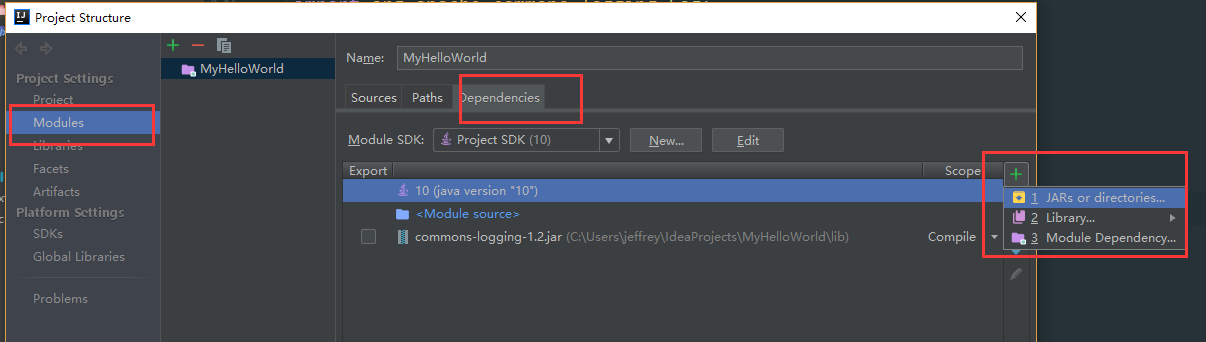
idea添加jar包的方法
- 点击file,project structure
- 点击左边的module,点击dependencies,点击add
- 选择其中的add jar,选中后确定即可
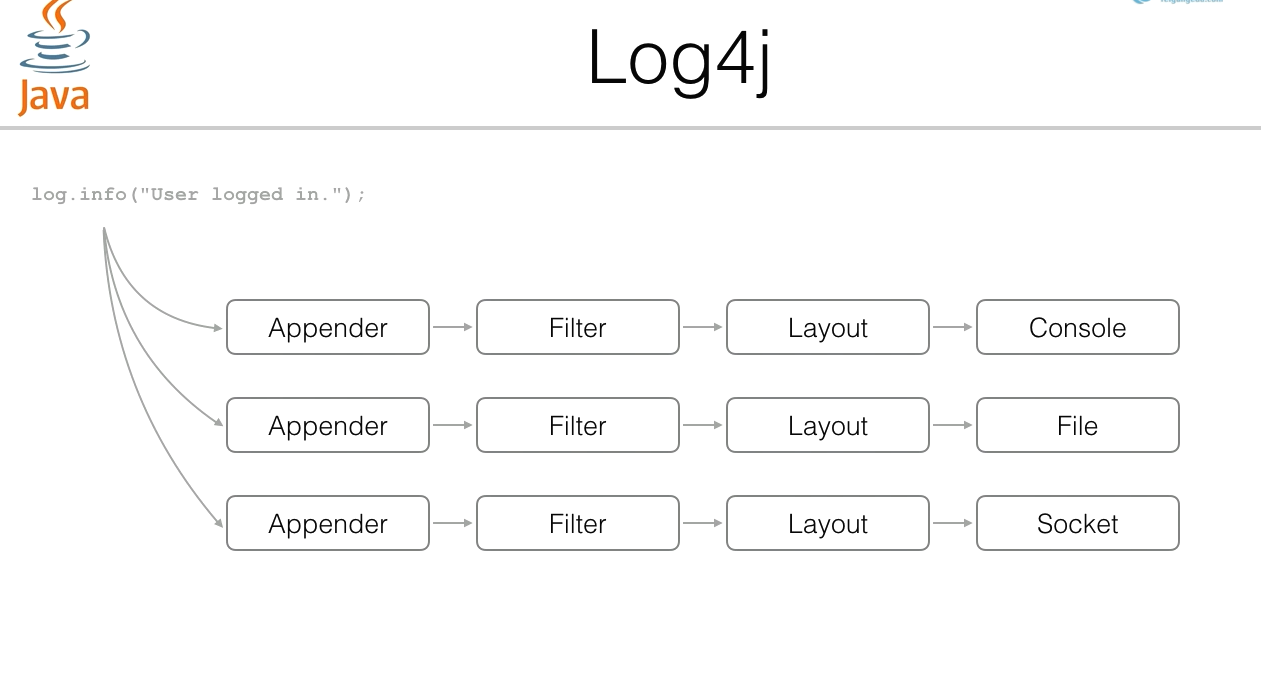
log4j
log4j是目前最流行的日志框架,其可以输出到控制台,文件(file),或者是远程(socket)
filter用于过滤:哪些日志需要输出,哪些日志不需要输出
layout:格式化输出
java反射与泛型
反射
class/interface的数据类型是Class
将通过Class实例来获取class信息的方法称为反射(reflection)——class实例–>class信息
1 | //方法1 |
反射的目的:获得某个object实例的时候,可以获得该object的class的所有信息
从class可以判断出class的类型,class提供以下几个方法:
1 | //1 |
判断类是否存在:
1 | Class.forName(name) |
通过class获取Constructor
1 | getConstructor(Class):获取某个public的Constructor |
通过反射获得继承关系
用class的getSuperclass()方法获取分类的class对象,注意:object和interface的父类是null
getInterfaces()方法返回当前对象的interface
通过class的isAssignabelFrom()方法可以判断一个向上转型是否正确
注解
注解是放在java源码的类、方法、字段、参数前的标签,用@开始,有点像python的装饰器
常用的注解包括:
@Override:检查是否覆写@Deprecated:告诉编译器该方法已经废弃,如果被调用出现警告@SuppressWarnings('unused'):抑制警告@Time(timeout=100):时间检查Check(min=0,max=100,value=55):值的检查
定义注解
用public @interface name来定义注解
元注解:注解可以修饰别的注解
用@Target定义Annotation可以被应用于源码的哪些位置
- 类或接口:ElementType.TYPE
- 字段:ElementType.FIELD
- 方法:ElementType.METHOD
- 构造方法:ElementType.CONSTRUCTOR
- 方法参数:ElementType.PARAMETER
1 |
|
Annotaiton的生命周期,用Retention()来定义

用@Repeatable定义Annotation是否可以重复
用@Inherited定义子类是否可以继承父类的Anootation
处理Annotation
通过反射可以处理注解,得到class对象后,可以用class.isAnnotationPresent(Class)来判断注解是否存在,用class.getAnnotation()得到Annotation
泛型
就是用<>来泛化某个类型,比如arraylist在使用过程中,你要指定这个list当中存放的元素类型,就要用ArraryList<String> al = new ArrayList<>();
集合
List
list是一种有序链表,每个元素都可以通过索引来确定位置
常用方法包括:

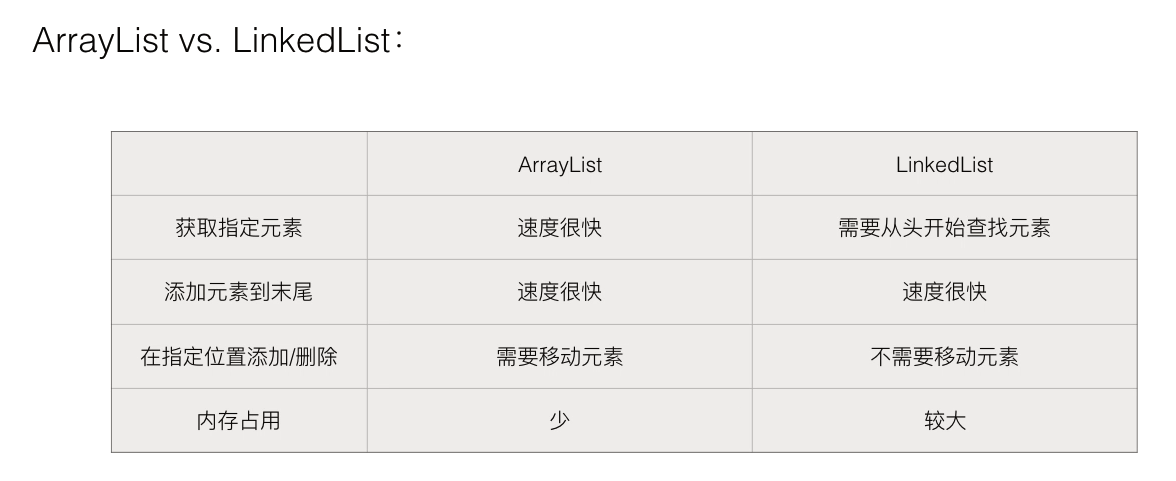
list的实现有ArrayList和LinkedList两种:
ArrayList就和数组是一样的结构,当添加的时候大小不够了,就创建一个更大数组,把之前的值全部复制过去,再加一个值
而LinkedList和链表一样的结构,上一个指向下一个
遍历list的方法
- get遍历
1 | List<String> list = new List<>(); |
- Iterator遍历
1 | List<String> list = new List<>(); |
- foreach循环,最推荐这种方法
1 | List<String> list = new List<>(); |
List和Array的转换
- Object[] toArray()
1 | List<Interger> list = new List<>(); |
<T> T[] toArray(T[] a)
1 | List<Interger> list = new List<>(); |
查找某个元素是否存在
- list.contains(Object o),返回true包含,false不包含
- list.indexOf(Object o),返回正数就是有,返回-1就是不存在
Map
map就是一种键值对映射的数据结构,与python中的dict是一样的
1 | public class Strudent{ |
map的常用方法
- put:将key-value对放入map
- get:通过key获取value
- containsKey:判断key是否存在
遍历Map的方法
- 遍历key
1 | Map<String,Student> map = ...; |
- 同时遍历key和value
1 | Map<String,Student> map = ...; |
HashMap和TreeMap
Map最常用的实现类是HashMap,其内部存储不保证有序
- 遍历时的顺序不一定是put的顺序,也不一定是key的顺序
SortedMap保证遍历时以key排序,其实现类是TreeMap
1 | Map<String,Integer> map = new TreeMap<>(); |
Set
set就是python里面的set,不包含重复值,常用方法包括
- add
- remove
- contains
- size
set不保证有序,HashSet是无序的,TreeSet是有序的
Queue
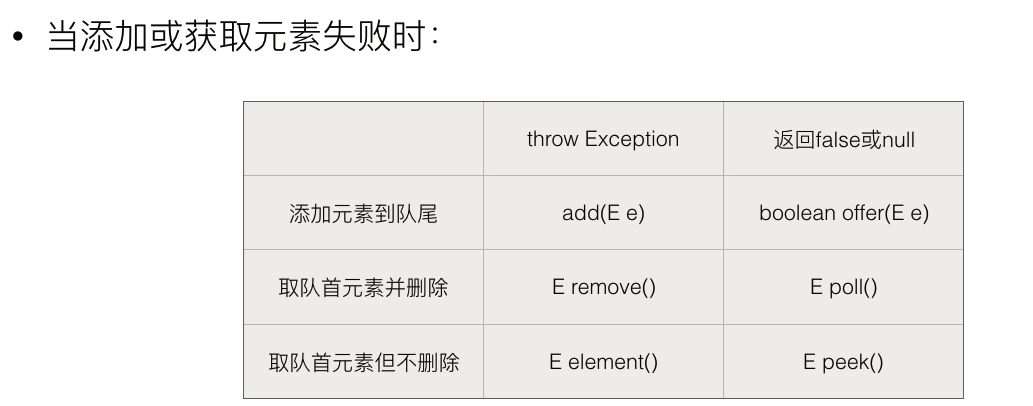
Queue是一个FIFO的队列,常用方法包括:
- size():获取长度
- 添加元素到队尾:add/offer
- 获取队列头部元素并删除:remove/poll
- 获取队列头部元素但不删除:element()/peek()
Queue的实现对象是LinkedList()
PriorityQueue
PriorityQueue就是带有优先级顺序的Queue,其常用方法与Queue相同
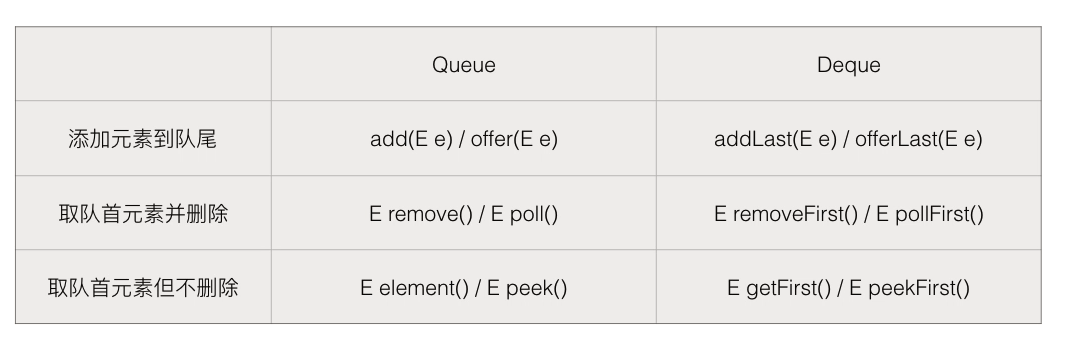
Deque
是Queue的一种实现,是双向队列
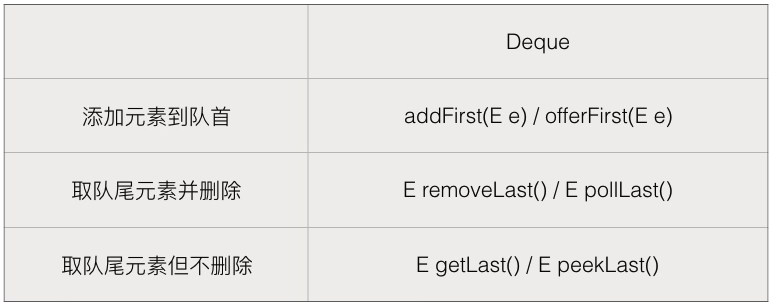
Stack
是一种LIFO(last In First out)的结构,常用方法
- push
- pop
- peek
使用Deque来实现stack,只调用push,pop,peek三个函数,这样就实现了栈
IO
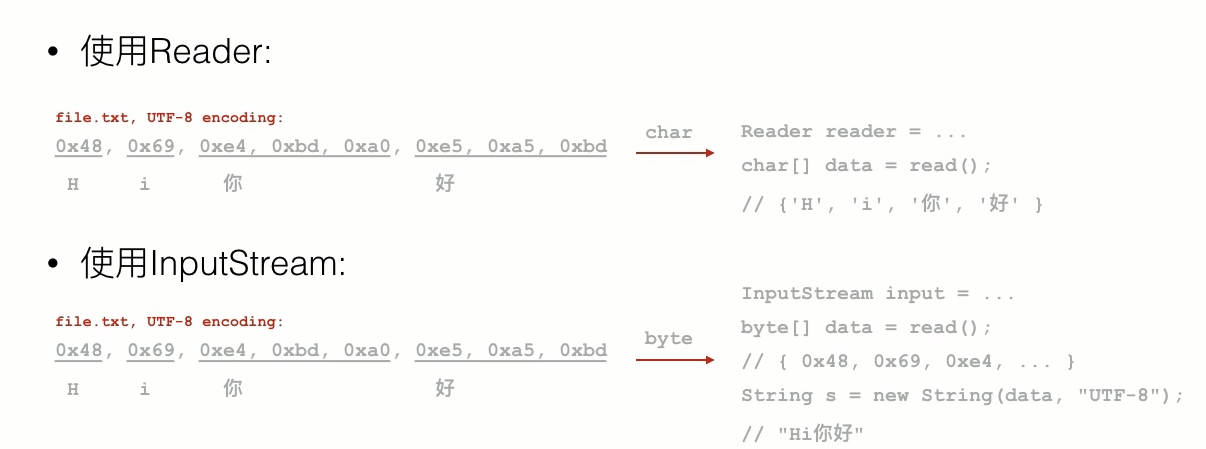
IO流,顺序读写数据的模式,单向流动,以字节为单位,byte类型
如果不是字节流,那么久用Reader/Writer表示字符流,字符流的最小单位是char,字符流输出的byte取决于编码方式
1 | char[] hello = "hi你好"; |
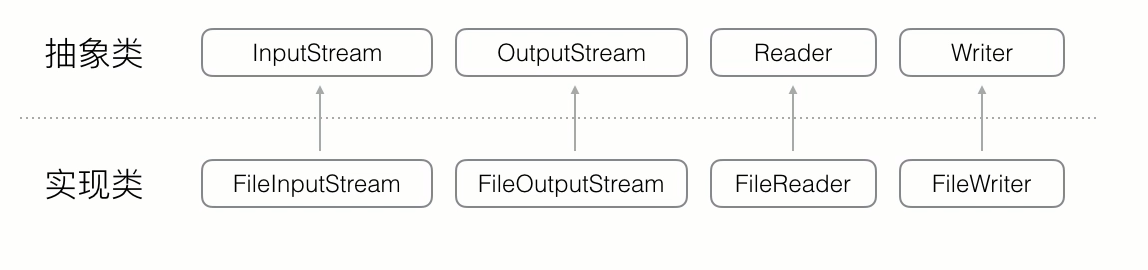
Reader/Writer本质上是一个能自动编解码的InputStream/OutputStream
其实现类如下:
File
构造方法
1 | File f = new File("c\\Windows\\notepad.txt") |
file有三种路径
1 | File file = new File("./Person.java"); |
规范路径就是绝对路径删掉.和..
用isFile()判断是否为文件,isDirectory()判断是否为目录
构造file对象就算是文件不存在也不会报错,因此要用上面两个文件来判断
canRead()/canWrite()用于判断是否可以读/写createNewFile():创建文件createTempFile():创建临时文件delete():删除文件deleteOnExit():在JVM退出时删除该文件String[] list():列出文件目录下的文件和子目录名File[] listFiles():列出文件和子目录名Boolon mkdir():创建目录Boolon mkdirs():创建目录,如果上层目录不存在,同样创建
InputStream
是所有输入流的超类,最重要的方法是abstract int read(),读取下一个字节,并返回字节(0-255),如果已经读到末尾,返回-1
完整读取一个inputstream流程如下:
- 方法1:用finally保证文件被关闭
1 | InputStream input = new FileInputStream("./src/test/a.txt"); |
- 用jdk1.7新增的try写法保证inputStream自动关闭,类似于python的with open(‘xxx’) as f
1 | try (InputStream input = new FileInputStream("./src/test/a.txt")) { |
- 用数组一次读取多个字节
1 | try (InputStream input = new FileInputStream("./src/test/a.txt")) { |
Reader/Writer
reader读取的是字符,其read方法读取下一个字符,读到末尾时返回-1
Writer读取的也是字符,write方法写入
java处理时间
计算机用时间戳来表示时间,这样全球统一表示,然后需要哪个时区的时候再转换为那个时区
java通常使用Date和Calendar处理时间,1.8之后使用LocalDate,LocalTime,ZonedDateTime,Instant
1 | Date date = new Date(); |
LocalDate
1 | LocalTime localTime = LocalTime.now(); |
用DateTimeFormatter来格式化时间
1 | DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss"); |
新api加入了时间增减的运算,plusDays()增加天数,minusHours()介绍小时
还加入了对时间的调整,比如你获取到了当前日期,你可以使用withDayOfMounth(1),把日期调整到本月的第一天,withMonth():调整到第几个月;还可以用with方法,计算本月的最后一天,方法如下
1 | //计算本月最后一天 |
还可以判断时间的先后
- isBefore()
- isAfter()
- equals()
得到当前的Period,就是一段时间间隔的Year,month,day
1 | LocalDate d1 = LocalDate.of(2014,3,12); |
ZonedDateTime
就是一个localtime加上一个时区ZoneId
1 | LocalDateTime d1 = LocalDateTime.of(2014,3,12,8,0); |
instant表示时刻
多线程编程
要启动一个新的线程,首先要创建一个新的线程对象
1 | Thread t = new Thread(); |
将自己的线程extends Thread,覆写其中的run方法
1 | public class MyThread extends Thread{ |
如果本身已经extends,就用implements Runnable,覆写其中的run方法
1 | public class MyThread implements Runnable{ |
一个实现的例子如下:
1 | System.out.println("Main start....."); |
线程状态
一个线程只能调用一次start
线程的状态如下:
- New:新创建
- Runnable:运行中
- Blocked:被阻塞
- Waiting:等待
- Timed Waiting:计时等待
- Terminated:终止
线程终止的原因有:
- run执行到return
- 因未捕获的异常终止
join
线程的join方法就是等待该线程结束,才继续向下运行
中断线程
中断线程需要检测一个isIterrupted标志,调用isIterrupte()方法中断线程
线程之间共享变量需要使用关键字volatile,确保线程能读到更新后的变量值
1 | public class Main { |
也可以用标志位来中断线程,要用到volatile关键字:
1 | class HelloThread extends Thread{ |
守护线程
守护线程的关键字是t.setDaemon(true)
守护线程是为其他线程服务的线程,守护线程在其他所有非守护线程结束的时候结束线程
守护线程不能持有任何资源(打开文件等)
如下,如果不使用守护线程,那么在主线程结束后,下面那个打印时间的线程就无法停下来
1 | public static void main(String[] args){ |
线程同步
当多个线程同时运行的时候,就需要对其同步,比如下面这个例子,对一个count+10000次,再-10000次,最终结果不为0,这是因为对共享变量写入的时候,必须是原子操作(不能被中断的操作),这时就需要线程同步。
1 | Public class Main{ |
不对的原因:加法的执行过程是load,add,store,如果中间被打断了,比如先执行了Thread 1的load,然后用了thread2的load,add,store操作,再回来执行thread的add操作,此时n仍然是100,因为已经load为100了,所以两次加法之后n只加了1次,等于101,因此必须加解锁

用synchronized对对象进行加锁,其他线程就算开始执行,没有获得锁,也无法执行
1 | synchronized(lock){ |
上面问题的加锁过程如下:
1 | public class Main{ |
Maven
Maven是一个项目管理工具,用于管理java代码及文件的编译,打包等过程
用Maven管理的项目路径如下:
