这篇博文主要讲的是关于deeplearning.ai的第三门课程的内容,《Structuring Machine Learning Projects》
Week one
机器学习策略简介
当你构建了一个机器学习系统,但是结果达不到你的要求的时候,你可能会尝试以下的方法
- collect more data
- collect more diverse training set
- train algorithm longer with gradient descent
- try Adam instead of gradient descent
- try bigger network
- try smaller network
- try dropout
- add L2 regularization
- network architecture
- activation functions
- # hidden units
- …
Orthogonalization(正交化)
正如同调整电视或者是汽车的控制一样,通常一个按钮用于调整一个方面,这样才方便调整到你希望的结果,如果一个按钮控制很多个方面,那么你很难将结果调整到合适
在机器学习的过程中,通常需要调整如下图的四个目标

- 首先是要在训练集上面表现够好(基本达到人工识别的水平),如果效果不够好,尝试更大的网络,或者好的优化算法比如Adam
- 第二要在dev set 上面表现够好,如果不过好,尝试正则化或者更大的训练集
- 其次在test set上面表现够好,如果不够好,需要尝试更大的dev set(因为你之前在dev set上面表现已经足够好了,但是在test set上面表现不够好,很可能是因为dev set取的太小了)
- 最后要求在现实世界的问题中表现够好,如果不够好,那么就要改变你的dev set 或者是 cost function,因为你之前在dev和test上用定义好的cost function已经能达到很好的结果,而在现实世界中不行,那可能就是你的cost function定义不够符合现实问题
设定目标
单一数值化评价矩阵
加入有A,B两个分类器,其精确率和召回率分别如下,精确率的定义是你分类为猫的样本中真正是猫的比例,召回率是所有是猫的图片最终被正确分类为猫的比例
两个定义倒不是非常重要,重要的是我们通常会需要在这两者当中做折中
如果你尝试了很多组超参的组合,你就需要不仅仅是在2个分类器之间选择,而是在十几个分类器之间选择了
为了能够同时照顾到精确率和召回率,引入一个F1 score,这个指标同时考虑了精确率和召回率

F1score 的定义是precision和recall的调和平均数(hormonic mean),表示为$F_1=\frac{2}{1/P+1/R}$,P和R分别表示精确率和召回率
满足(statisficing)和优化(optimizing)矩阵
加入你现在有两个系统,第一个是用来分类猫图片的,但是又要考虑时间;第二个是用来唤醒关键字的,要同时考虑准确率和false positive(没有说话但是被唤醒了)

第一个猫图片系统可以用<=100ms的值的最大精确度来衡量
第二个可以用在24小时内被唤醒小于等于1次的,最大化精度的系统
训练,开发,测试集的分布
开发集和测试集需要来自于同一个分布,如果不同,你在开发集上面得到了很好的精度,运用到测试集的时候,就相当于是找另外一个问题的最优值,这样效果一般来说都不够好
在传统的机器学习项目中,因为数据量不是很大,比如有100个,1000个或者10000个数据,通常train和test的比例是7 0%和30%,如果需要dev set的情况就是60%train,20%dev,20%test
在数据量比较大的时候,比如100w条数据的时候,可能98%的train,1%的dev和test,因为1w条dev和test已经绰绰有余了
改变dev/test setd和评估矩阵
比如你现在有一个分类猫图片的分类器,其中一个错误率低,但是存在一些色情图片,这个时候就要改变你的评估矩阵,加入一个系数,这个系数当图片不是色情图片的时候为1,是色情图片的时候为10或者100,这样如果是色情图片,错误率就会变得很高,实现了你的要求

再来看个例子,假如你的分类器的dev和test的数据都是高清的猫图片,而最后应用的时候的图片的质量都很差,此时你分不出来猫图片,这个时候我们就要考虑改变dev/test set,或者改变评价指标
与人工分辨水平的比较
当你的系统超过了人类的精度的时候,可能就接近一个称之为贝叶斯优化错误或者是贝叶斯错误的值了,这个值是理论上的最佳精度,你不论如何用更复杂的模型或者是调参都无法逾越这个值
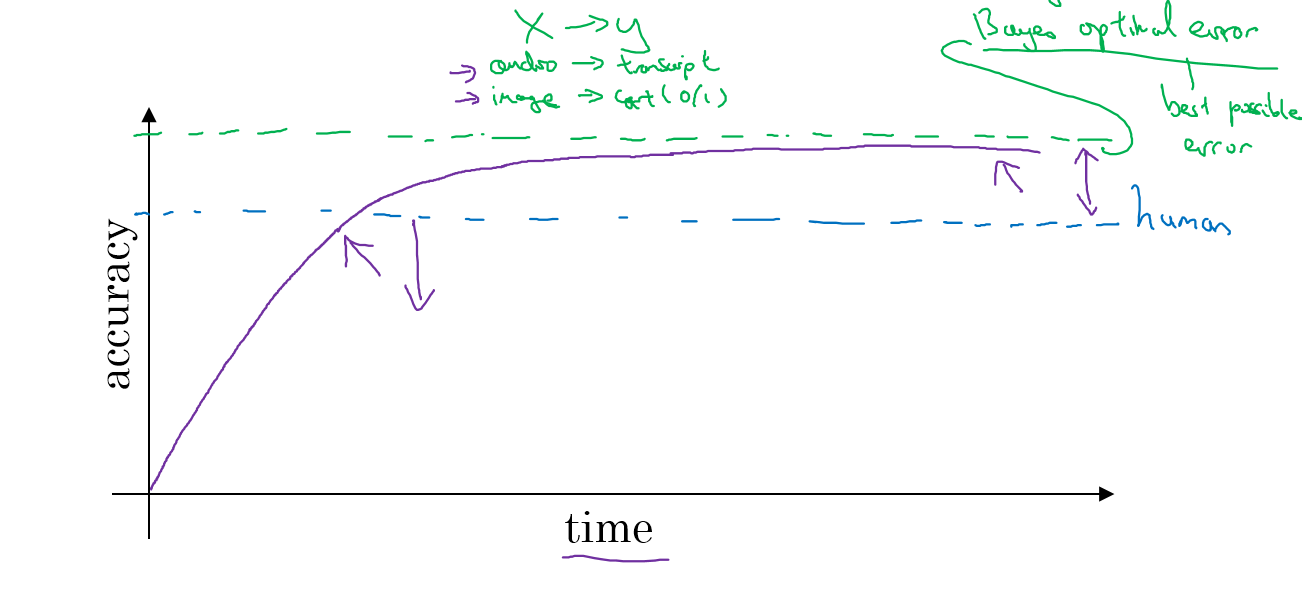
与人类相比的原因是因为人类擅长很多方面,只要你的系统还不如人类做得好,你就可以用人工标注出更多的数据,以及分析为什么人工做的比机器好,更好的分析偏差和方差
可避免的偏差和方差
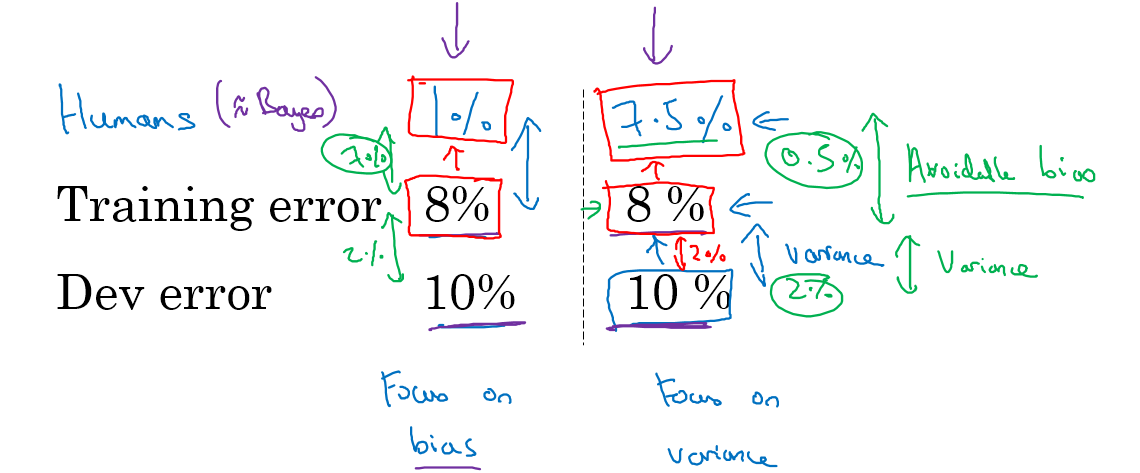
训练集误差和贝叶斯误差之间的距离成为可避免的偏差,训练集误差和开发集误差之间的差距成为可避免的偏差,如下图所示
两者当中,哪个大我们就专注于减少哪一个
超过人工水平
人类尤其擅长感知任务,比如图片分类,自然语言处理和语音识别,机器更擅长数据挖掘,找寻数字规律等任务
机器在感知领域能够超越人工水平是非常棒的效果,现在越来越多领域已经可以超越人类
改进模型效果的策略
如下图,改进模型表现,主要有两点,首先是可以在训练集上面表现的很好,然后是扩展到开发集和测试集

具体来说,对于不同的问题,有如下的策略

Week Two
错误分析
加入你现在建立了一个分类猫的分类器,但是你发现其中有些狗的图片也被分成了猫,那么你是否需要去找更多的狗的图片并标记好,放在你的训练样本中呢?
这个时候我们就需要进行错误分析,看看我们对某个方向的努力是否值得
错误分析的步骤:
- 找出100个错误标记的开发集样例
- 计算这里有多少张本来是狗,结果分成了猫的情况
如果这里100张分错的样例中只有5张是狗,那么也就是5%的错误原因来源于狗的图片。如果你之前的错误率是10%,那么你最多也就只能减少5%,达到9.5%,这显然不太值得去做
如果这100张分错的样例中有50张是狗,那么就是50%的错误原因来源于狗的图片。如果你之前错误率是10%,那么现在可以减少50%,达到5%,这就值得去做了
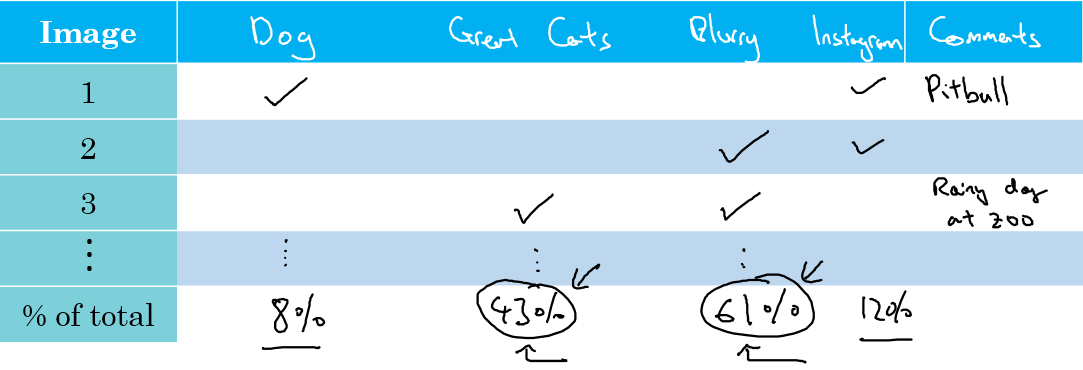
当然,我们可能会找到很多个方向去优化,比如在猫的分类器的问题中:
- 解决狗被分成猫的情况
- 解决大型猫科动物(狮子,老虎等等)被认为是猫的情况
- 解决模糊图片分错的问题
这个时候,我们找出大概100张分错的图片,然后列一个表格,对每个分错的图片进行归因,最终得到每个因素的影响的比例,为我们提供改进的参考,如下图:
清理标记错误的数据
当训练集中存在标记错误的数据的时候,只要比例不是很大,深度学习系统是可以克服这样的情况的
当开发集和测试集中存在错误标记的数据的时候,我们就把错误标记也看作一个影响因素,然后加入一列在上面的错误分析表中,如果影响大则去纠正,否则就先纠正别的

快速建立你的第一个系统,并迭代
假如你现在正在建立一个语音识别的系统,你可能考虑很多下图左边的影响,比如背景噪声,方言的影响等等。
但是正确的做法应该如右边所示,首先建立一个开发和测试集以及评价矩阵,然后快速建立一个系统,之后使用偏差/方差分析和错误分析来进行迭代,优化你的系统

不匹配的训练和开发/测试集数据
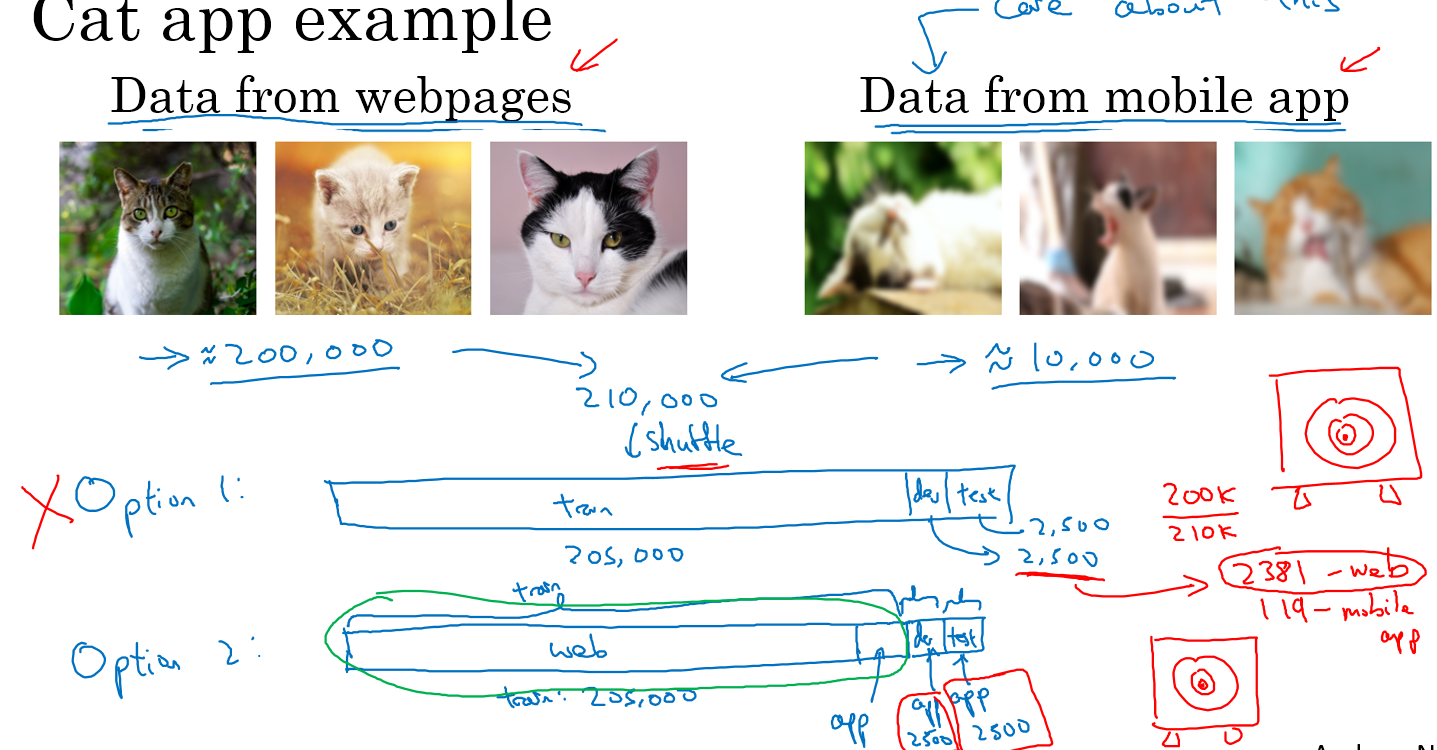
假设你现在有一个分类猫的app,你能从网上找到的猫图片都是高清的,但是用户用手机上传的都是不够清晰的,这时就有一个训练与开发/测试集数据不匹配的问题
假设你能从网上找到20w张高清猫图,而用户那种模糊的图只有1w张
现在有两种方案:
- 随机混合所有数据,用20500张训练,2500张开发集,2500张测试集
- 将20w张高清图和5k张模糊图用于训练,2500张模糊图作为开发集,2500张模糊图作为测试集
显然第一种方法是错误的,因为如果你随机混合之后,2500张开发集中只有119张来自于模糊图,你最终的目标是去识别模糊图中的猫,这样一来目标就设置错了
因此我们选用第二种方法
再假设你现在在开发一个语音激活的后视镜系统,你有别的语音数据50w条,而语音控制后视镜的你有2w条,那么正确的方法应该是50w条语音加上1w条控制语音作为训练,5k条控制语言作为开发集,5k条控制语言作为测试集
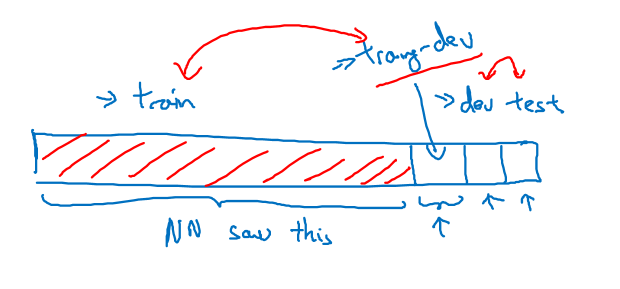
不同分布数据的偏差/方差分析
假设你现在有一个猫分类器,training error是1%,dev error 是10%。同时,你已经知道你的训练数据和dev/test数据分布不同,训练图清晰,dev/test数据不清晰。那么你这个1%到10%的差距,到底来源于high variance还是来自于数据的不匹配呢?此时就说不清了
我们在可能存在数据不匹配的情况下,再划分一个training-dev set,用于衡量究竟是high variance 还是数据不匹配对系统造成了印象,分类方式如下图,原来的train set分成了train和training-dev,原来的dev和test不变
接下来在新的train set上面训练,并用training-dev set和dev/test set进行测试,根据结果来判断到底是high variance造成的问题,还是数据不匹配造成的问题,那么怎么判断呢,我们来看几个例子
例1. 你现在的training error 是1%,training-dev error是9%,dev error 是10%,可以看到,即使数据分布相同时,数据的variance依然很高,所以我们先处理high variance的问题
例2. 你现在的training error 是1%,training-dev error是1.5%,dev error 是10%。可以看到,数据分布相同时的差距很小,而数据分布不同的时候差距很大, 应该着重处理数据失配(missmatch)问题
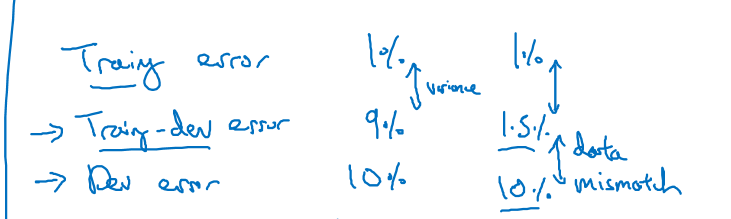
human error和training error之间的差距是avoid bias,需要更复杂的模型或者超参数
traning error 和 training-dev error之间的差距是high variance,需要正则化
training-dev error 和 dev error之间的差距是data missmatch
dev error 和 test error 之间的差距是 overfitting dev set,要找一个更大的dev error
解决data missmatch
解决data missmatch的方法,总体来说就是构造与dev/test相同分布的数据
我们举个例子,比如你现在有很多安静环境下的录音,同时还有少量汽车噪音下的录音,我们最终的dev/test数据是这个汽车噪音下的录音,因此我们可以将安静环境下的录音与单纯的汽车噪音混合,这样我们就快要得到更多汽车噪音下的数据
但是在混合的时候也要注意,比如你现在有10000小时的安静录音,1小时的汽车噪音,你将这1小时的汽车噪音重复到10000次得到10000小时的汽车噪音,这对人耳来说可能是正常的,但是对于深度学习算法来说,可以就会对这1小时的汽车噪声产生过拟合。因此正确的做法是尽可能收集10000小时的汽车噪声,然后与这10000小时的安静录音混合。
迁移学习
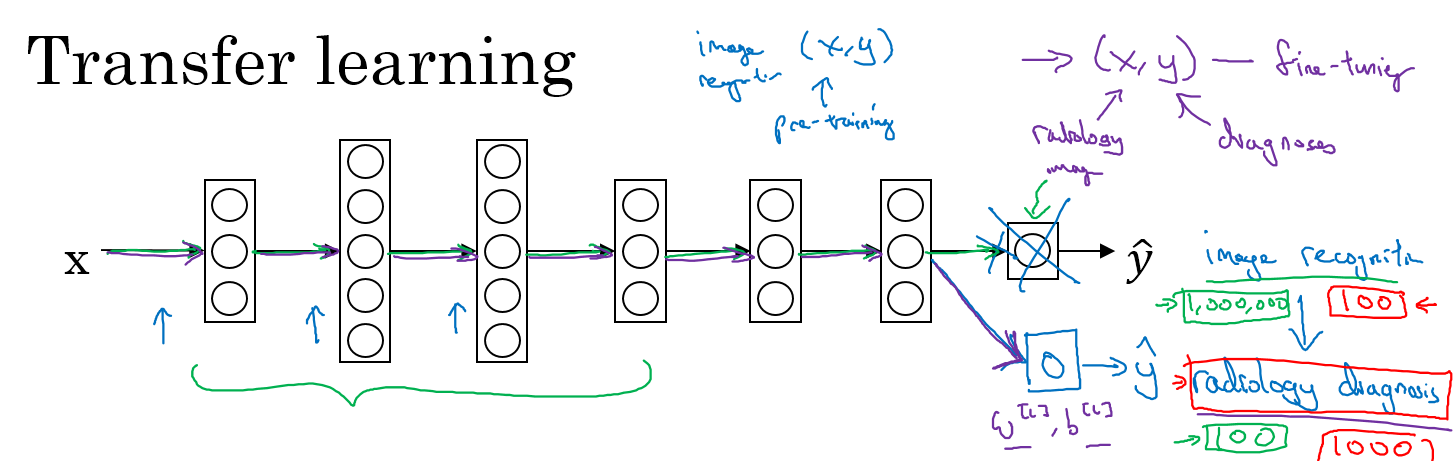
假如你现在有两个任务A和B,你有大量的A的数据,只有少量B的数据,但是你最终想要去识别B,此时,只要A和B是同一类的数据(比如都是图片,或者都是语音),那么我们就可以使用迁移学习
迁移学习就是用数据量大的A数据先构建模型,然后去掉输出层(数据量非常少的时候,如果数据量稍微多一些,可以多去掉几层),用数据量少的B的数据进行训练,最终这个系统能够很好地分类B
举个例子,比如你现在有个分类猫的分类器,但是你想要能够分类x光,那么你先用猫的数据建立分类猫的分类器,然后去掉输出层,再用x光的数据进行训练,就得到了一个分类x光的分类器
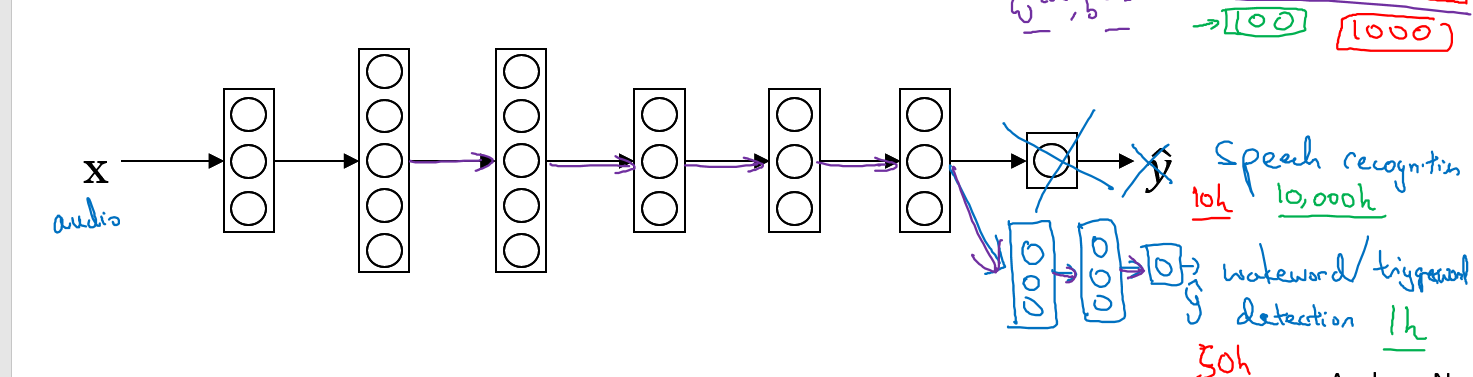
再比如说你有一个语音识别的分类器,现在要建立一个唤醒词的分类器,那么你只需要去掉输出层,然后再训练唤醒词分类器即可,这个唤醒词分类器可以只有1层,也可以扩展为好几层
多任务学习
假设你正在做一个自动驾驶物体检测的问题,检测一张图上是否有行人,车辆,路标和交通灯,如果有则标记出来,比如下面这张图的标记为y=(0,1,1,0)
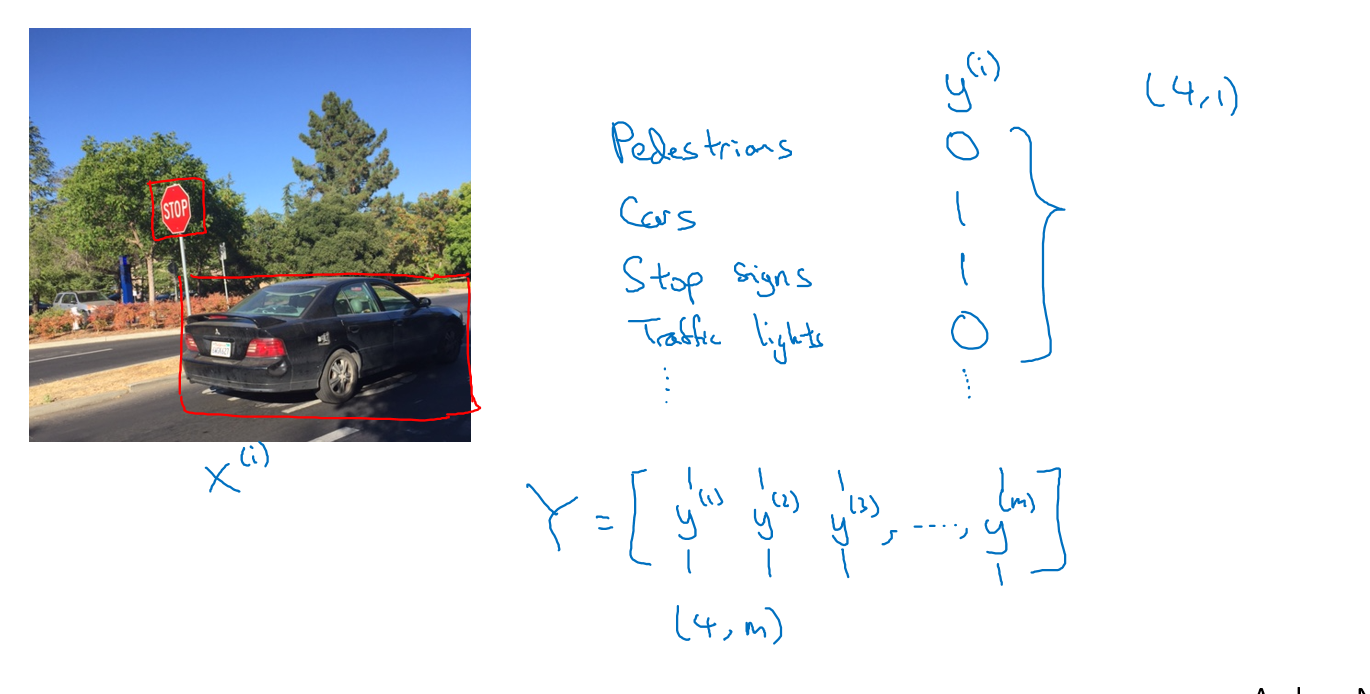
所谓的多任务学习就是一次学习出的分类器可以分类多个目标,比如上述的问题,我们把四个的loss放到一起,甚至有些分类没有标记也是可以学习的,你只需要在计算loss的时候只算标记好的类型,如下图
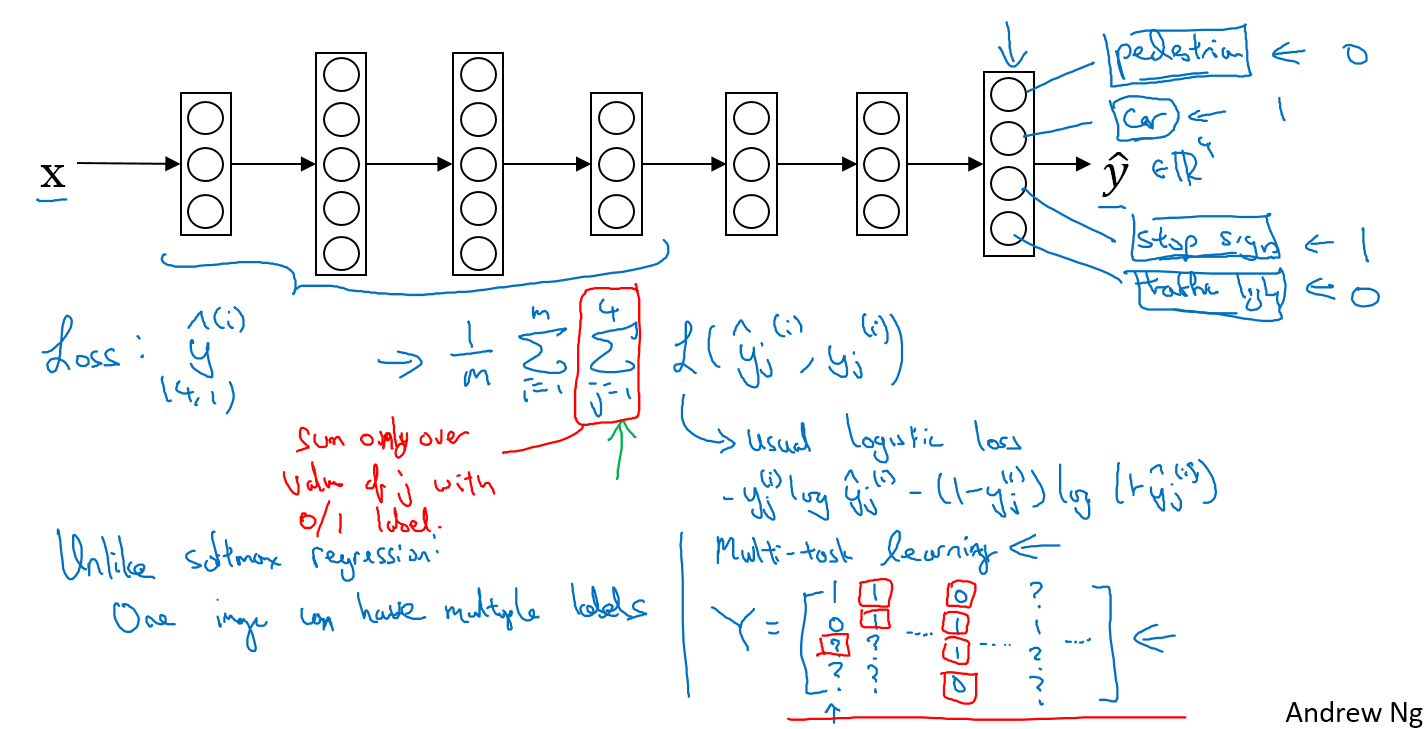
多任务学习和softmax回归的区别:多分类可以有多个类别是1,而softmax回归只能有一个类别为1
端到端的深度学习
传统的机器学习方法,是输入原始数据,然后分好几步提取特征,最终得到分类结果
端到端的学习,就是直接输入原始数据,得到最终的分类结果,这是需要大量的数据作为支撑的
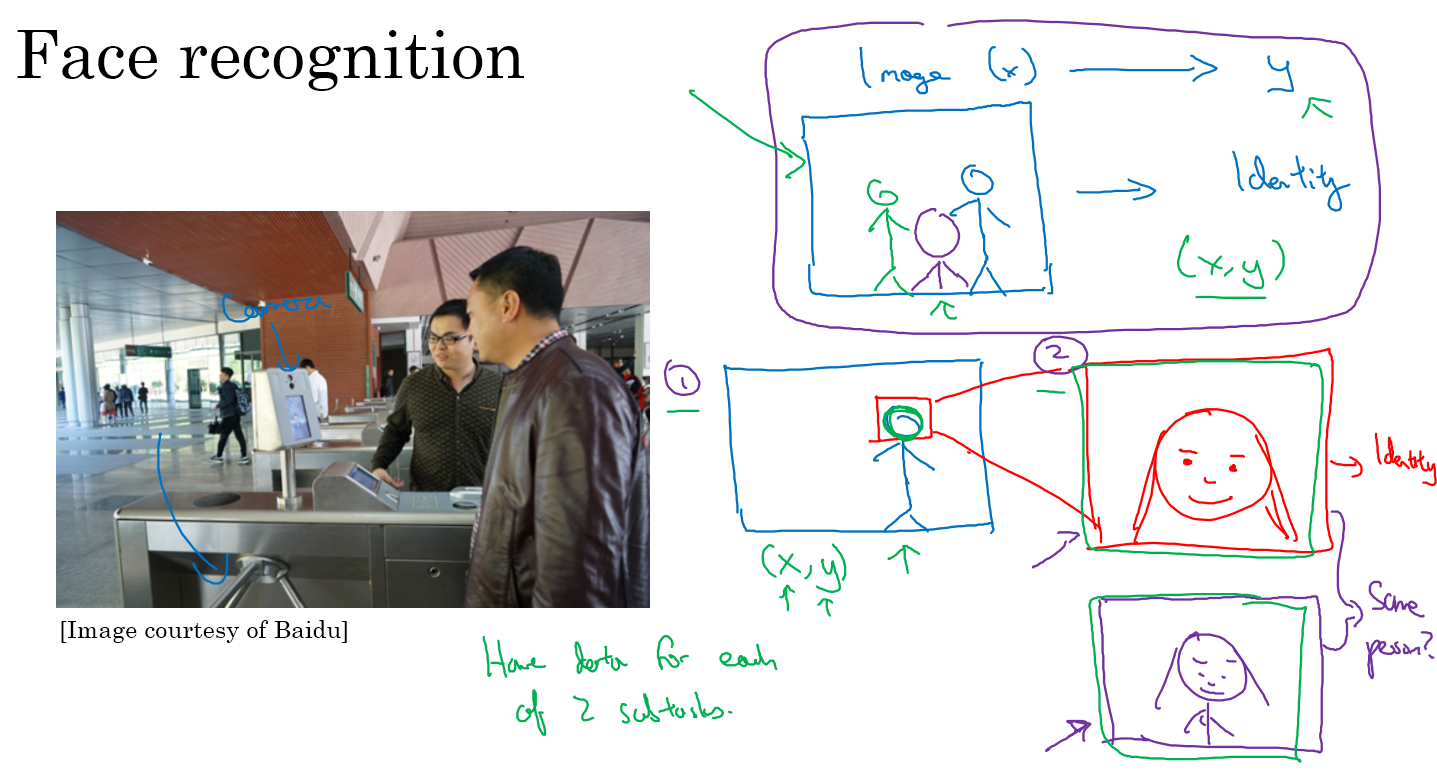
举个例子,在人脸识别这个问题中,你是不能使用端到端的方法的,因为在人脸识别的时候,人脸可能处于图中任何位置,因此没有这么多的数据支撑你进行端到端的识别。你应该分成两个子任务,首先是提取出人脸这个任务,然后再是人脸的比较任务
再比如机器翻译这个任务,用端到端的方法是很合适的,因为翻译的数据足够多,可以支撑你的端到端方法

决定是否使用端到端的方法
端到端学习的优劣势
优势:
- 数据自我解释
- 很少的需要动手去设计的中间步骤
劣势:
- 需要大量数据
- 不能使用手动设计的步骤中的有效内容
是否使用端到端的方法,最主要的问题就是你是否有足够的数据去找出x到y的映射
比如在自动驾驶的过程中,目标检测的过程我们用的是深度学习的方法,在路径规划的时候用的是motion planning 的方法,然后到如何控制油门刹车,方向盘之类的时候用的是控制学