机器学习分类
- unsupervised learning
Clustering —k-Means
—Hierarchical Cluster Analysis (HCA)-层次聚类分析
—Expectation Maximization
Visualization and dimensionality reduction 降维方法
—Principal Component Analysis (PCA)主成成分分析
—Kernel PCA
—Locally-Linear Embedding (LLE) 局部线性嵌入
—t-distributed Stochastic Neighbor Embedding (t-SNE) t分布随机近邻嵌入
Association rule learning 关联规则挖掘
—Apriori 算法
—Eclat(大成功)
Semisupervised learning(半监督学习)
大量无标签数据和少量标记数据
照片标记的时候
强化学习
奖励和惩罚机制
批学习和在线学习(batch learning and online learning)
从是否用新到来的数据进行学习来区分
- 批学习每次把所有数据都放进去学习,如果数据集过大则不适用
- 在线学习:每次学习之后可以删除数据,占用计算资源也少
- 学习率:接收新数据,以及遗忘旧数据的频率
基于实例的学习和基于模型的学习
- 基于实例的学习:在邮件标记系统中,比较新邮件与已标记为垃圾邮件的相似度,由此来决定是否为垃圾邮件
- 基于模型的学习:先训练出模型(比如线性模型或者是多项式模型之类的),然后将新的数据输入模型得到结果
机器学习问题解决思路
frame the problem
搞清楚真正的目标是什么。如何用结果去帮公司盈利之类的。
A sequence of data processing components is called a data pipeline.
data pipeline:一系列的数据处理组件被称为数据管道
随机排列数:np.random.permutation()
如果要固定随机的方式,可以在一开始使用np.random.seed(42)
train_test_split:把数据集按比例分成训练集和测试集
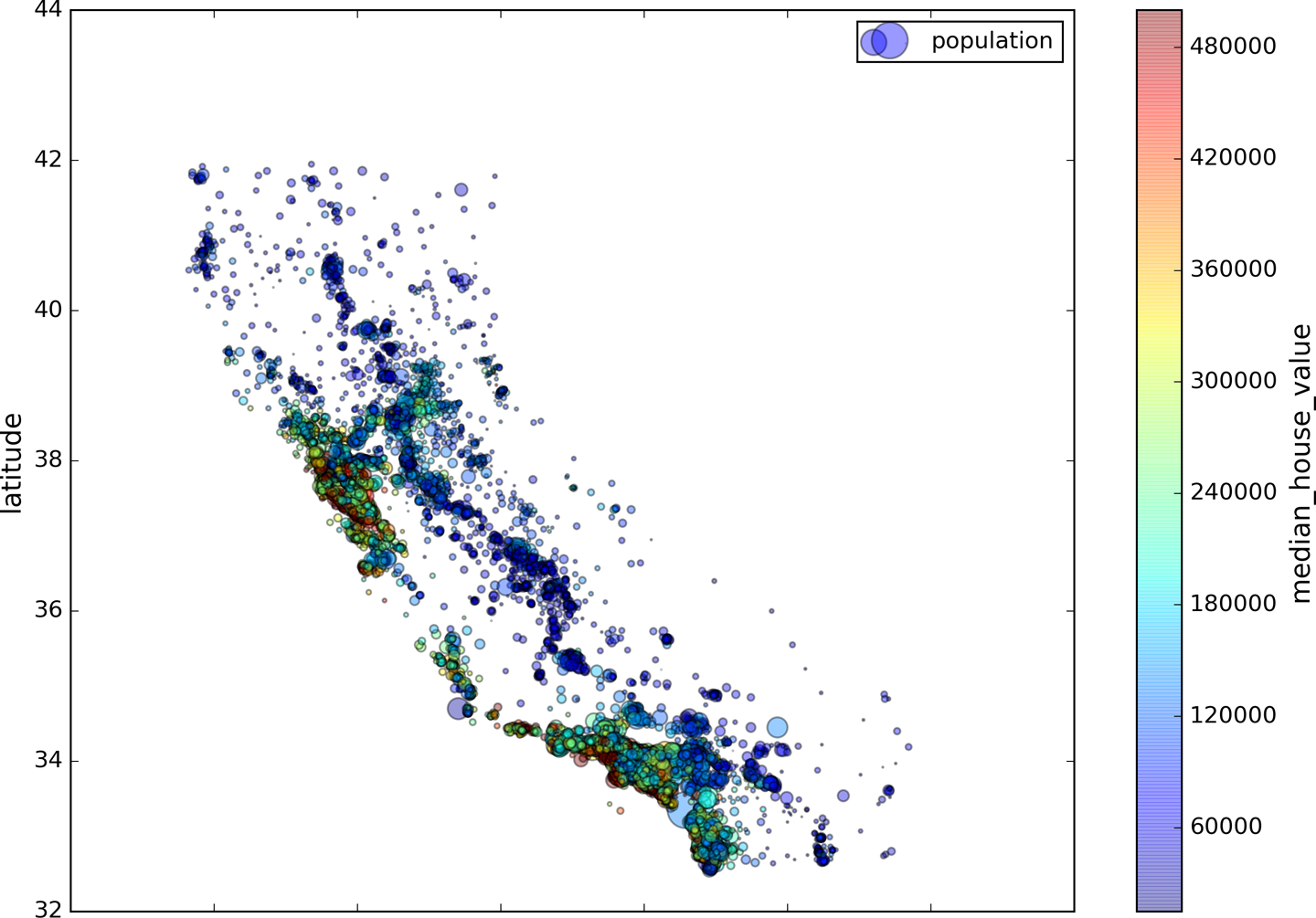
绘制带有colorbar的图,用圈的大小表示人口数量,用颜色表示放假的高低,红色最高,蓝色最低
1 | housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, |