kaggle是一个国外的数据挖掘竞赛平台,大家做完竞赛之后会写一些指导,因此可以通过其他人写的指导文件进行学习,kaggle传送门。
其中有一个入门类的分析问题是分析Titanic号的救援问题,分析哪些因素会影响到是否被救援,首先打开Titanic这个问题的具体页面,Titanic: Machine Learning from Disaster,
先看一看overview里面的description和evaluation,看看问题背景和最终需要预测的内容,然后点击数据,下载三个csv格式的数据集,第一个train.csv是训练集,第二个test.csv是测试集,第三个gender_submission.csv是验证集,
下载好之后打开pycharm,新建名为Titanic的工程,新建Titanic.py开始进行分析
首先,导入需要用到的包
1 | import numpy as np |
接下来导入数据
1 | train_data = pd.read_csv('train.csv') |
查看数据的信息
1 | train_data.info() |
得到的数据信息如下
1 | <class 'pandas.core.frame.DataFrame'> |
一共是891行,12列,其中Age列和Cabin列还有Embarked列数据不完整,每一列的含义如下:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
然后我们可以看看各个数据的统计值
1 | train_data.describe() |
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 714 | 891 | 891 | 891 |
| mean | 446 | 0.383838 | 2.308642 | 29.69912 | 0.523008 | 0.381594 | 32.20421 |
| std | 257.3538 | 0.486592 | 0.836071 | 14.5265 | 1.102743 | 0.806057 | 49.69343 |
| min | 1 | 0 | 1 | 0.42 | 0 | 0 | 0 |
| 25% | 223.5 | 0 | 2 | 20.125 | 0 | 0 | 7.9104 |
| 50% | 446 | 0 | 3 | 28 | 0 | 0 | 14.4542 |
| 75% | 668.5 | 1 | 3 | 38 | 1 | 0 | 31 |
| max | 891 | 1 | 3 | 80 | 8 | 6 | 512.3292 |
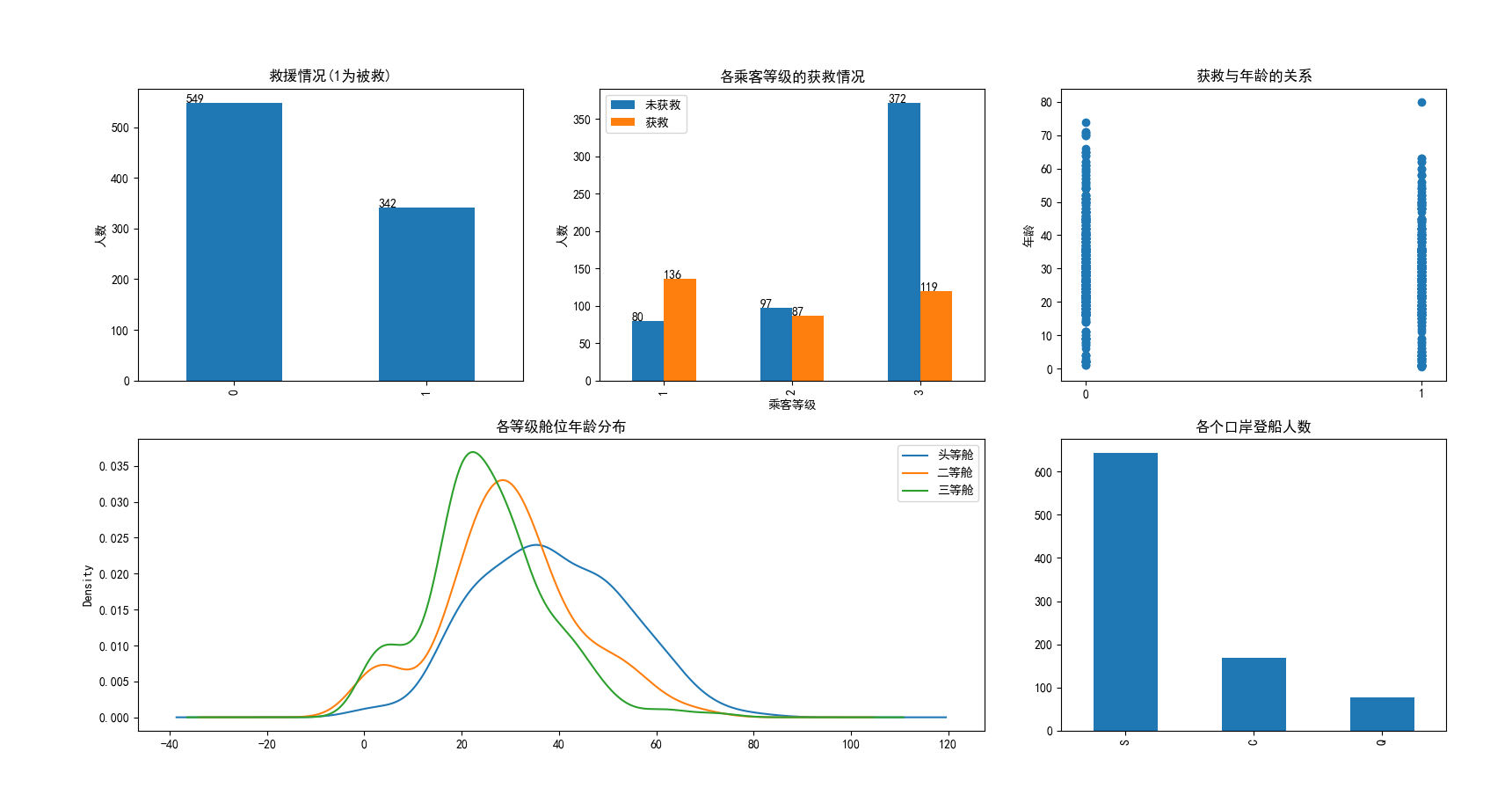
得到一个如图的描述,可以看到被救援的人数只有38%,且二,三等舱位人数居多,平均年龄29岁
这样得到的数据有一定的参考性,但是这么多个属性,究竟哪些和最终被救援有关系呢,我们可以画出图像来进行更加形象的描述
所有DataFrame类型的数据都可以在其后面直接调用plot函数,然后在其中输入kind来选择图的类型,绘制代码如下,
1 | ## 绘制被救情况 |
绘制得到的图片如下:
其中标注直方图的代码为:
1 | def Annotate(fig,plus_times=1.005): |
接下来具体看看每个属性和是否被救援的关系
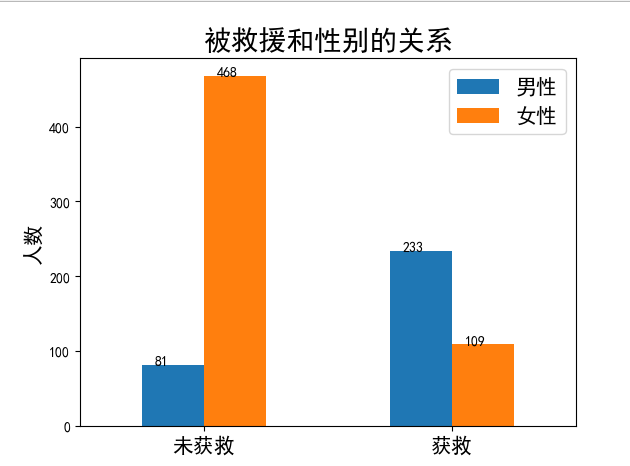
首先画出被救援和性别之间的关系
1 | survived_m = train_data.Survived[train_data.Sex == 'male'].value_counts() |
其中的字体大小设置可以用ctrl+B跳到原始代码中去看,大多数情况都是直接设置fontsize
舱位级别和性别对获救的影响
1 | fig = plt.figure() |
接下来画出登船港口与是否获救的关系:
1 | def Annotate(fig,plus_times=1.005): |
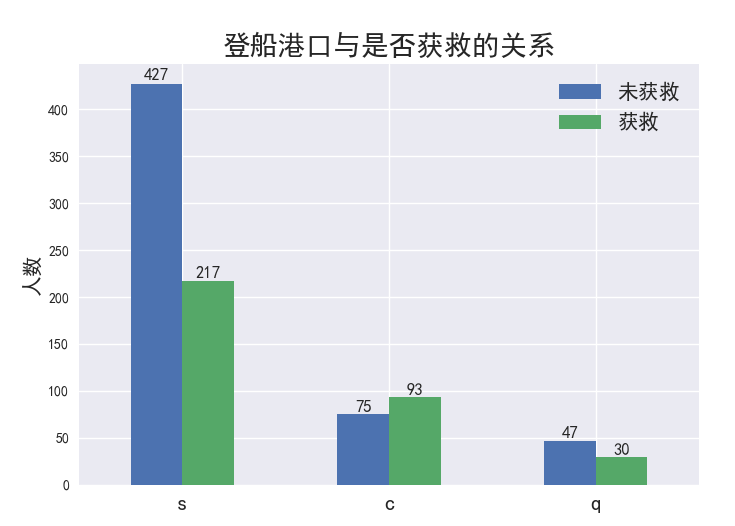
接下来画出堂兄弟姐妹对是否获救的影响:
1 | # 堂兄弟/妹对是否获救的影响 |
pandas选取偶数行和奇数行分别为:df.iloc[::2], df.iloc[1::2]
要获得Mutiindex的值只需要:df.index.values
下面看看cabin这个参数,这个参数的缺失很多,并且值的种类实在是太多了,基本是每个值都不同,我们要把这个参数作为一个特征的话,也许可以试试cabin是否缺失作为特征
1 | survived_cabin = train_data.Survived[pd.notnull(train_data.Cabin)].value_counts() |
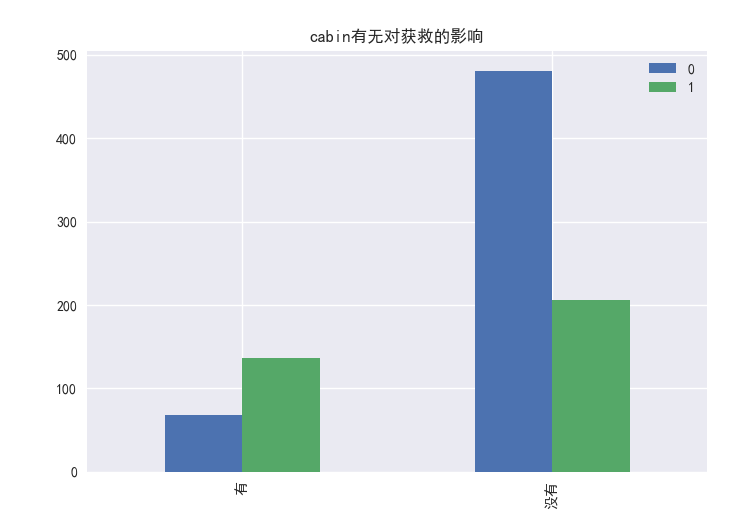
看来有cabin这个参数更容易获救
因此我们需要将Cabin的有无转化为bool型变量:
1 | # 将cabin的有无转化为bool型变量 |
使用RandomForest Regression 对年龄数据进行拟合
因为年龄数据差的比较多,所以我们想到要将年龄数据进行补全,所以想到了拟合年龄的曲线,在这里我们使用的方法是RandomForestRegressor
1 | from sklearn.ensemble import RandomForestRegressor |
将非数字的值转化为数字
pandas提供了一个get_dummies函数,可以直接把可以分类的数据转换为多个成标量值,比如下面的将Cabin转化为了Cabin_yes 和Cabin_no:
1 | dummies_Cabin = pd.get_dummies(train_data['Cabin'], prefix='Cabin') |
连接两个DataFrame
只要用pd.concat([df1,df2], axis=1),就可以按列连接
1 | train_data = pd.concat([train_data,dummies_Cabin,dummies_Embarked,dummies_Sex,dummies_Pclass],axis=1) |
删除某些列
直接df.drop(['column1','column2'], axis=1, inplace=True),就是按列删除,并且inplace=True表示将原来的df直接替换成删除掉某些列之后的数据
1 | train_data.drop(['Name','Sex','Ticket','Cabin','Embarked'],axis=1, inplace=True) |
数据归一化
使用sklearn.preprocessing包的preprocessing函数,先定义一个scaler实例,用preprocessing的StandardScaler,用scaler先fit出你想要归一化的那一列的参数,然后用fit_transform进行归一化,传入的参数是需要归一化的值和归一化参数
1 | #数据预处理 |
逻辑回归预测
计算完这些部分,将测试数据导入并进行与训练数据相同的预处理,然后进行逻辑回归预测,先用train_data进行fit,然后用训练数据的x进行预测
1 | from sklearn import linear_model |
检验预测精度
因为我们一开始在进行测试数据预处理的时候,删除了一行,所以在比较的时候应该把这一行补上,在补充完毕之后index是乱的,所以我们直接reset_index,并且sort_values,按照PassengerId排序
1 | auth_df = pd.read_csv('gender_submission.csv') |
精度得到为0.9330143540669856