scrapy是一个完整的爬虫框架,一共有5个部分组成和2个中间部分,最主要的是一下五个部分:
- ENGINE
- SCHEDULER
- ITEM PIPELINES
- SPIDERS
- DOWNLOADER
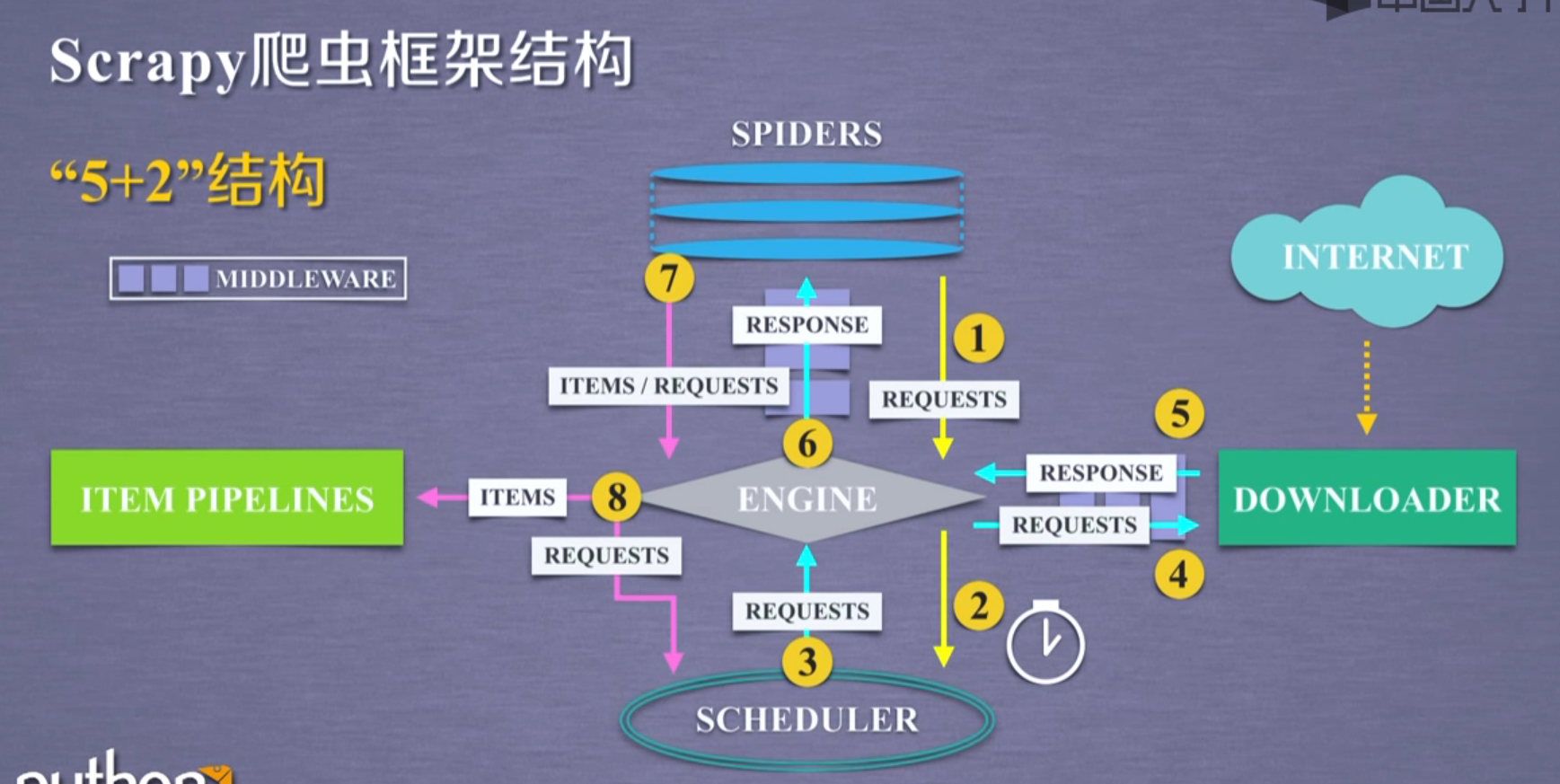
用户主要编写spider和item pipelines,其余三个模块是事先写好的,不需要修改
可以通过修改downloader middleware中间键来对engine,scheduler和Downloader进行配置
scrapy通过命令行运行
1 | scrapy command [options] [args] |
scrapy有6个常用命令
- startproject:创建一个新的工程
- genspider:创建一个爬虫
- settings:获得爬虫配置信息
- crawl:运行一个爬虫
- list:列出工程中所有爬虫
- shell:启动url调试命令行
建立一个scrapy工程的方法
1 | scrapy startproject python123demo |

建立完成之后可以看到的文件夹下产生了一个名为python123的文件,进入该文件可以看到一个scrapy.cfg的文件,这是一个部署scrapy的配置文件
1 | │ scrapy.cfg |
文件树目录如下, 在windows中通过tree /F python123demo查看
使用如下命令生成名为demo的爬虫,爬取的网页为python123.io
scrapy genspider demo python123.io
产生的demo.py如下
1 | import scrapy |
scrapy的request类里面有一下几个方法:
- .url:request对应的请求url地址
- .method:对应的请求方法,’GET’,’POST’等等
- .headers:字典类型的请求头
- .body:请求内容主体,字符串类型
- .meta:用户添加的扩展信息,在scrapy内部模块间传递信息使用
- .copy():复制该请求
Rsponse类7个常用方法:
- .url:response对应的url地址
- .status:状态码,默认是200
- .headers:response头部信息
- .body:response对应的内容信息,字符串类型
- .flags:一组标记
- request:产生Response类型对应的request对象
- .copy():复制该响应
实例
爬取股票数据
步骤一
1 | scrapy startproject BaiduStocks |
步骤二
修改spider文件夹下的stocks.py文件
1 | import scrapy |
通过东方财富网获得stock的代码,然后同过百度股票爬取信息,其中parse和perser_stock函数都通过yield变成生成器
第三步
更改pipeline.py,用于数据处理,定义一个新的处理数据的类称为BaiduStockInfoPipeline,定义open_spider,close_spider,以及process_item三个函数
1 | class BaiduStockInfoPipeline(object): |
第四步
修改settings.py,把ITEM_PIPELINES里面用到的类改为自己定义的BaiduStockInfoPipeline:
1 | ITEM_PIPELINES = { |