首先,需要理解cookies的含义,是存储在浏览器中的内容,在本地存储任意键值对,第一次访问时服务器返回一个id存储到本地cookie中,第二次访问将cookies一起发送到服务器中

常见http状态码
| code | 说明 |
|---|---|
| 200 | 请求成功 |
| 301/302 | 永久重定向/临时重定向 |
| 403 | 没有权限访问 |
| 404 | 没有对应的资源 |
| 500 | 服务器错误 |
| 503 | 服务器停机或正在维护 |
要爬取知乎内容首先需要进行登录,在本文中我们主要介绍2种登录方式,第一种是通过requests的session保存cookies进行登录,第二种是通过scrapy修改start_requests函数进行登录
requests进行登录
在utils中新建zhihu_login.py,实例化一个session对象,设置其cookies对象为cookiesjar库中的LWPCookieJar对象,设置requests库需要用到的headrs(从浏览器中进行拷贝),
1 | session = requests.session() |
接下来,我们要寻找登录发送数据的页面,首先打开zhihu.com退出之前的登录,来到一个登录页面,在登陆页面中使用手机号码登录,此时需要发送一个错误的信息给页面,以找到post数据的网页(如果输入正确的账号密码就直接登录成功了,一大堆网页请求就找不到我们需要的网页了)
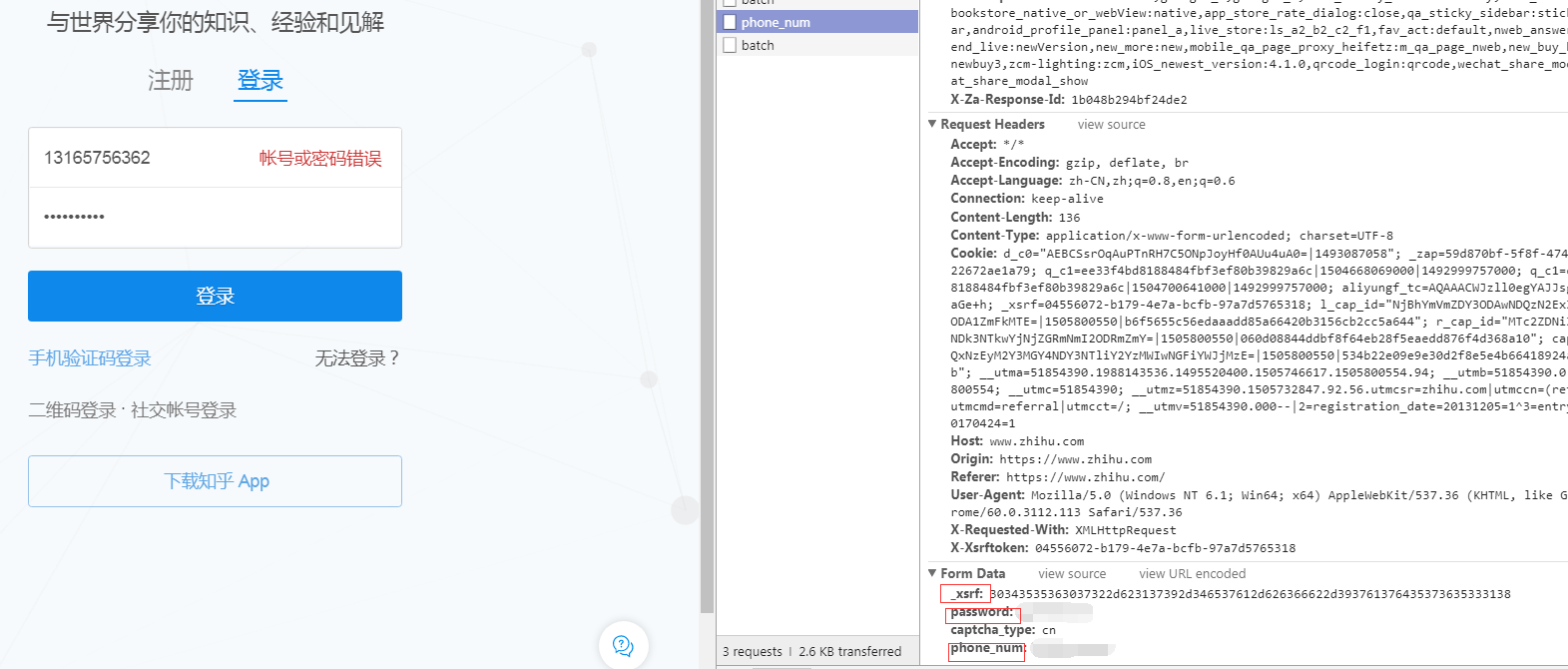
找到了需要post的网页,发现post的数据有_xsrf,passoword,phone_num,另外一个captcha_type没有用,加了之后反而无法访问(不知道为什么)
1 | def zhihu_login(account, password): |
在这里我们一开始没有使用验证码,发现只要是爬虫登录都会被识别到,所以我们编写了一个用于生成验证码的代码:
1 | def get_captcha(): |
保存完cookies,我们尝试使用这个cookies再次登录
1 | def get_again(): |
查看这个页面发现不停地刷新,暂时还没有找到办法
scrapy模拟登陆知乎
首先生成一个新的spider,名字为zhihu
在class zhihu中定义headers等信息,重写start_requests函数
1 | def start_requests(self): |
在start_requests里面返回一个新的Request,其回调函数设置为一个新的login函数如下:
1 | def login(self,response): |