request库,主要用于网络爬虫
首先通过pip install request安装request库
写一个简单的入门程序,访问以下百度首页:
1 | import requests |
request库一共有7个主要方法
- requests.request():构造一个请求
- requests.get():获取网页
- requests.head():获取网页头信息
- requests.post():向网页提交post方法
- requests.put():向网页提交put方法
- requests.patch():向网页提交局部修改请求
- requests.delete():向网页提交删除请求
最常见的五个网页response属性:
- status_code:200表示成功
- text:http响应内容的字符串形式
- encoding:从http header中猜测的响应内容编码方式
- apparent_encoding:从内容解析出的响应内容编码方式(备选编码方式)
- r.content:响应内容的二进制形式
一般是先判断status_code,如果是200再进行找text和content
requests库可以看做只有一个函数,那就是requests.request()方法,只是第一个参数分别换为’GET’,’POST’等等。
request参数一共有如下13个字段:
- params:获取网页的方法
- data:字典,字节序列或文件
- json
- headers参数可以模拟浏览器,
- cookies可以从http协议中解析cookie,
- auth:提供http认证
- timeout指设置的超时时间,proxies设置代理服务器(字典类型)
- allow_redirects:是否允许重定向
- stream:内容立即下载开关
- verify:认证ssl开关
- cert:本地存放正数地址
基础的网页爬取代码框架:
1 | try: |
首先用request.get获取网页内容,同时设置timeout为30,r.raise_for_status()表示如果状态码不为200则报异常,设置encoding方式为apparent_encoding,最后返回r.text
一定要在try,except里面进行,网页访问是常常出错的
使用Beautifulsopu解析网页
主要是用于网页代码解析,第一个参数指定网页代码,第二个参数指定使用的解析器
一共有4类常用的解析器:分别是’html.parser’,'lxml'要先安装lxml, 'xml'要先安装lxml,'html5lib'要先安装html5lib
用法如下:
1 | Beautifulsoup(r.text,'html.parser') |
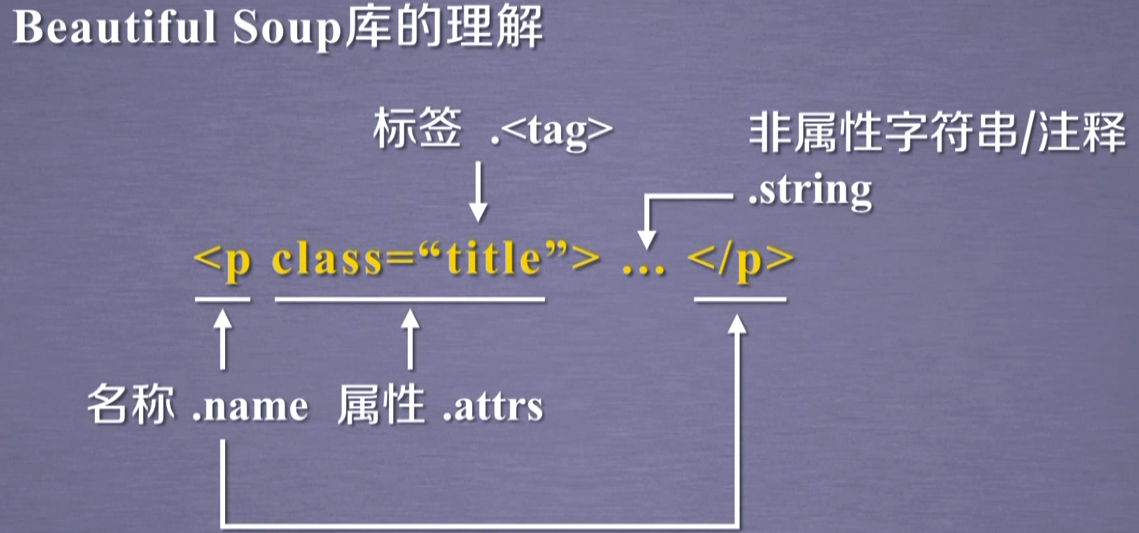
Beautifulsoup的基本元素
- tag:标签
<></> - name:标签的名字
- Attribute:标签的属性,字典形式,格式
<tag>.attrs - NavigableString:标签内分数性字符串
<tag>.attrs - Comment:标签内字符串的注释部分
一共有3种遍历方式,上行,下行,平行遍历
下行遍历有3种
- .contents:子节点的列表,将所有儿子节点存入列表
- children:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants:子孙节点的迭代烈性,包含所有子孙节点,用于循环遍历
上行遍历有2种
- .parent:节点的父亲标签
- .parents:节点先辈标签的迭代类型,用于循环遍历先辈节点
上行遍历的代码
1
2
3
4
5
6soup = BeautifulSoup(demo, 'html.parser')
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)平行遍历有4种
- .next_sibling:返回按照HTML文本书序的下一个平行节点标签
- .previous_sibling:上一个平行节点标签
- next_siblings:迭代类型,返回后续所有平行节点标签
- previous_siblings:迭代类型,返回前续所有平行节点标签
prettyfy方法用于更好地打印标签
数据标记
xml:类似于HTML格式
json:JavaScript object notation,用键值对的形式记录数据,比如
1
2
3
4
5
6
7"name" : "xi'an jiaotong"
"address": "xi'an"
# 用大括号表示嵌套的键值对
"university{
"name": "jiaotong",
"address":"xi'an"
}json的键值对都是有类型的
yaml格式是无类型的,用缩进进行所属,用法:
1 | uninversity: |
通过BeautifulSoup数据获取
通过find_all函数找到所有的标签,通过.get获得某个具体的属性
1 | soup = BeautifulSoup(r.text,'html.parser') |
如果查找多个标签,可以把标签部分用列表放入soup.find_all(['a','b'])
第二个参数可以放属性,比如id=link1
第三个参数是recursive:表示是否对子孙节点进行检索,默认为是
第四个参数是string,查找某个string,结合正则表达式可以进行搜索
同样,find_all也有find,find_parent,find_next_sibling之类的方法
格式化输出时如果遇到中文不对齐的情况:用chr(12288)作为填充:
1 | print("{0:^10} \t {1:{3}^10} \t {2:{3}^10}".format('排名','学校名称','省市',chr(12288))) |